It's never just a data warehouse
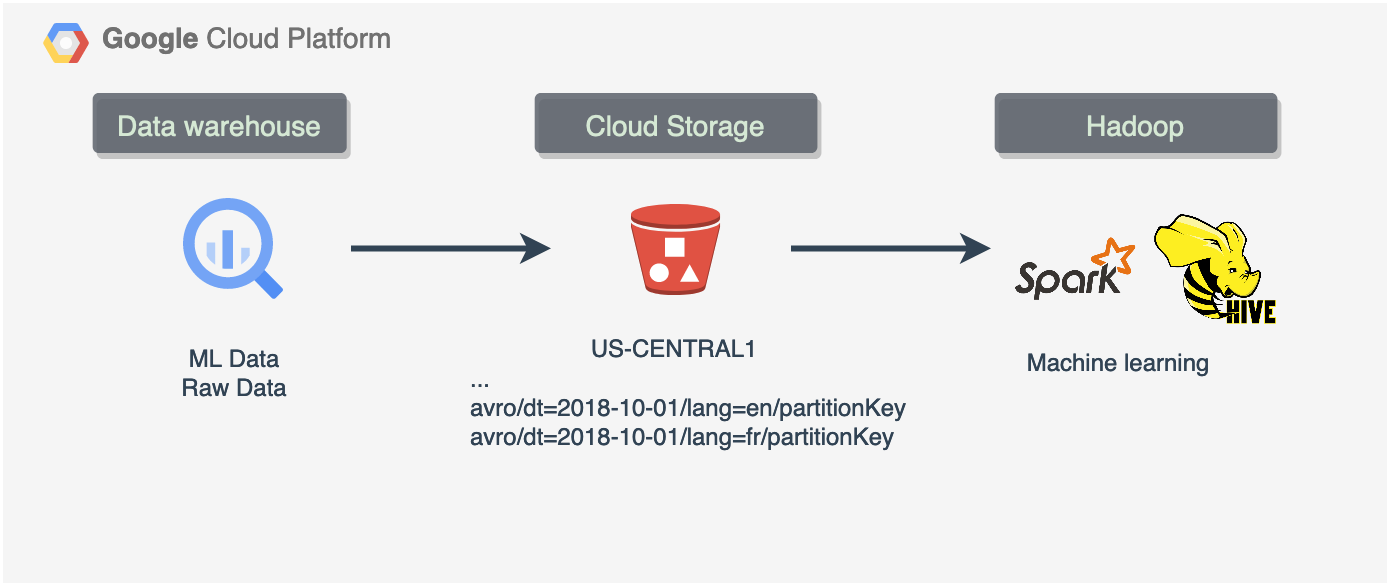
Yet another way to improve our data solution. If your data platform architecture requires a data lake then this article is for you.
Code snippets you will find below explain how to Export data using AVRO, Parquet or JSON and create externally partitioned tables in case you need to add a bit of a data mesh component and process datasets using data lake tools, like EMR and Hadoop. Feel free to use this code to create a data lake infrastructure including storage and partition layouts.
This article will help also if you want to optimise data warehouse Storage costs
You will find the comparison and code to unload the data and automate the process.
It's never just a data warehouse and depending on your data platform architecture type you might want to use something different to process and transform the data.
Data pipeline design defines the selection of tools to use and at some point we might want to keep a portion of data in the lake rather than a data warehouse.
I previously wrote about common data pipeline design patterns here:
So why use external tables in the first place?
Storage cost optimisation is one reason to try it. Another reason could be something like a new Machine learning pipeline where a model trainer would use the data from the lake. In that case we will need externally partitioned tables to pass it to Spark application or something else that scales well.
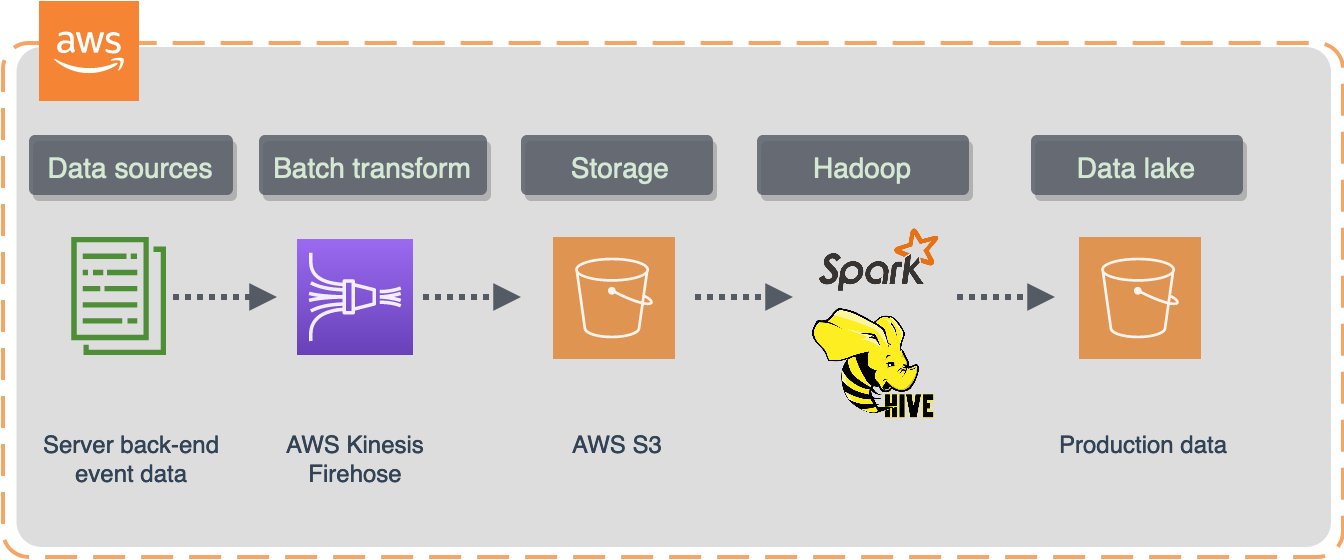
Typically, it is a very rare scenario when a company would use only one data processing/transformation solution. Data mesh came to our life quickly with a variety of data tools and storage types.
For example, I saw companies processing the data using data lake tools in the first place and then loading the results into a production schema somewhere else, i.e data warehouse. After that Business Intelligence (BI) team would pick up from there creating their own OLAP cubes in BI tools like Looker, Sisense, Mode, etc.
My data platform is a lake house. Main data transformation scripts run in the data warehouse solution which is Google BigQuery following ELT pattern.
However, there is a reason I still want to keep a portion of data in the lake. Firstly, keeping the data in the data lake helps to investigate data loading errors, and we can store data for just a couple of days in a standard storage type bucket after ingestion into the data warehouse. Secondly, we might want to unload historical data we no longer interested in to optimise storage costs.
In this article I will scribble down some code snippets and scripts to load/unload data from data warehouse in different file formats such as Parquet, AVRO, JSON, ORC. I will compare storage costs in the data warehouse with archive type storage.
Unload and archive data warehouse data with ease
Sometimes we need to export some data warehouse tables to Storage. There might be various reasons for that including data migration, Storage cost optimisation, new data tools, new pipelines, etc.
Most of the modern data warehouse solutions provide data export features with SQL or Python. I will use Google Bigquery as an example.
There is currently no charge for exporting data from BigQuery, but exports are subject to BigQuery's Quotas and limits.
I work with Firebase event data a lot, and these tables are expensive.
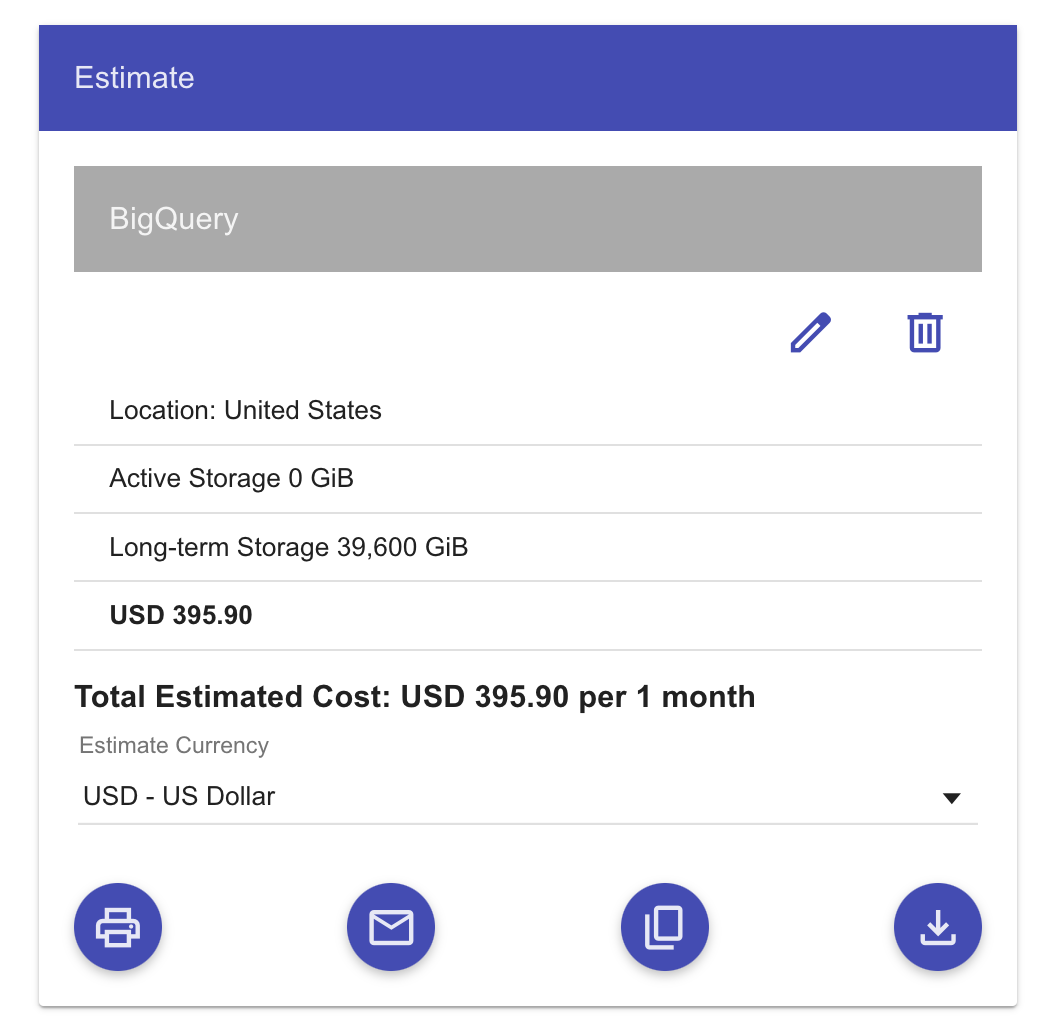
They are usually quite heavy and contain a lot of user engagement data. So in my case raw event data have been building up over the last couple of years, started to generate some considerable costs and reached a critical point of somewhat around $2600 a month just for the long-term storage in BigQuery.
The decision was made to keep only the most recent data for 90 days and unload everything else older than that to Cloud Storage archive.
The idea behind this is to query historical data directly from Cloud Storage only if needed using external tables on partitioned data.
Storage costs
This is definitely something you would want to consider building a data warehouse.
For example, in BigQuery everything older than 90 days goes to long-term storage.
At some point we might want to archive our data. We can achieve this by unloading data into Cloud Storage. Should we choose to export our table data, it has to be located in the same region as Cloud Storage bucket.
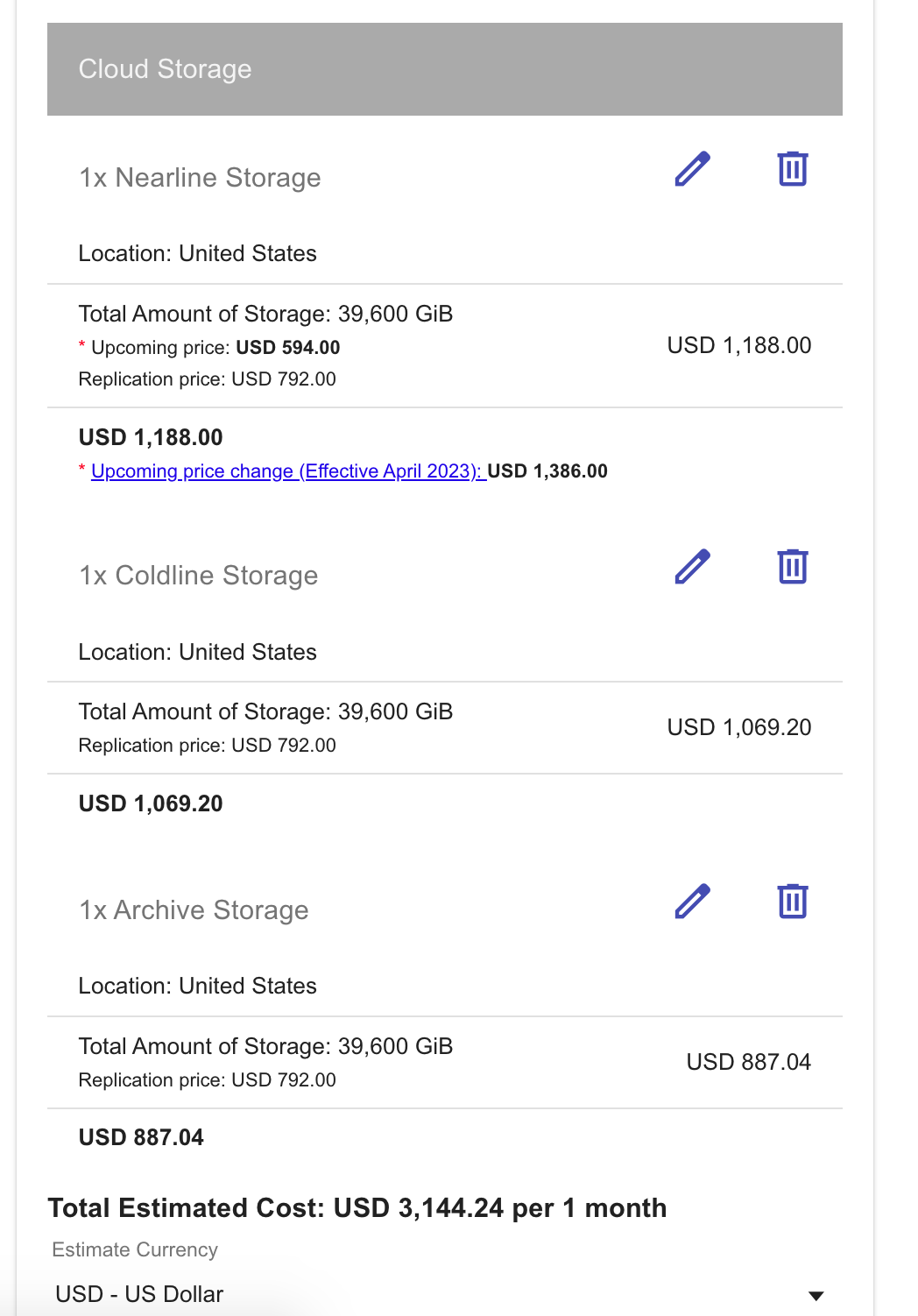
Depending on a bucket type we get a different price. Multi-regional buckets are expensive compared to single-region ones.
Everything has to be colocated in the same region if we want it work at 100% capacity
This includes data transfers, moving data between storage buckets, etc.
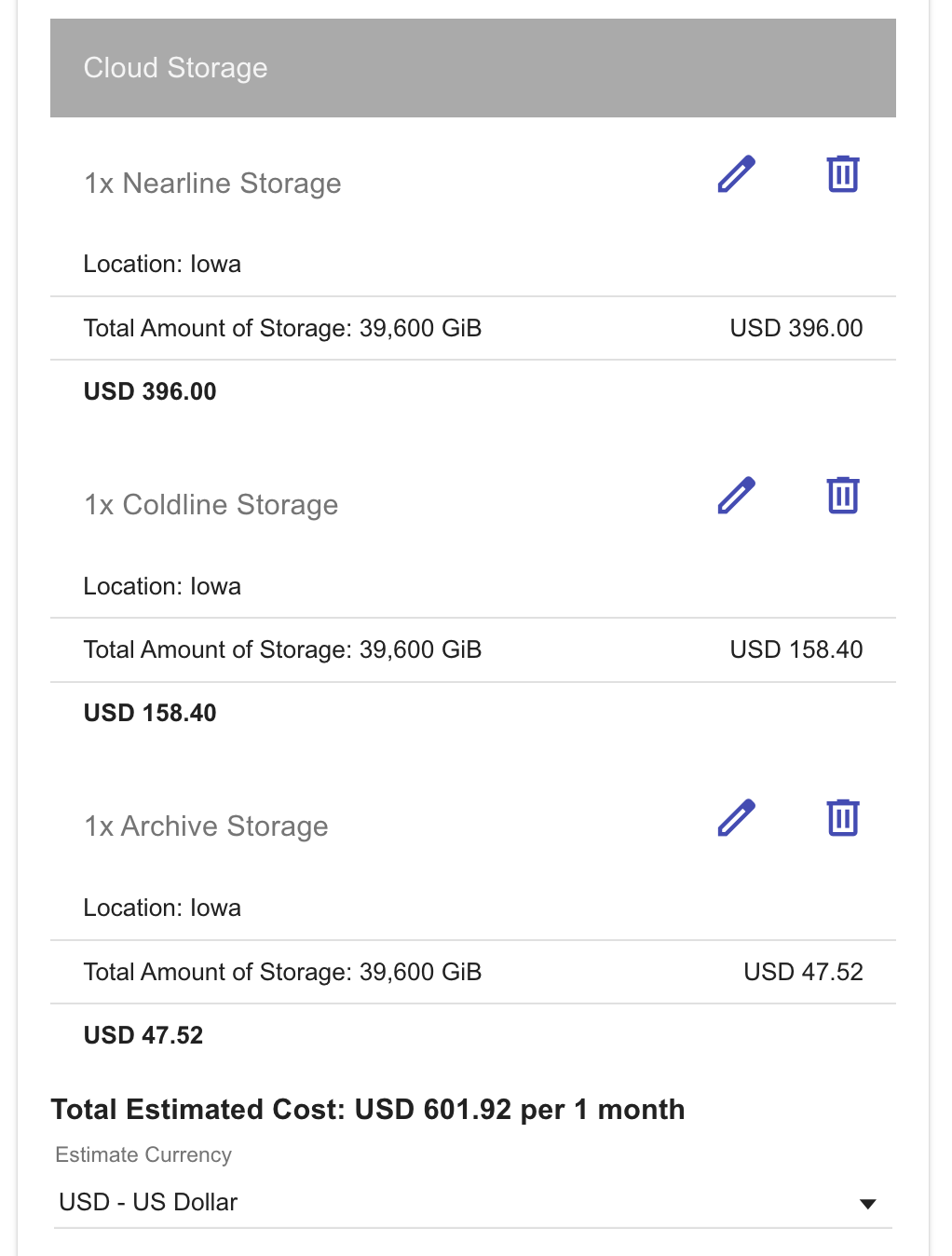
We can see that BigQuery long-term storage costs are similar to Nearline Storage costs for a single-region bucket.
So for example, if we have a Firebase dataset in US (multiple regions) in BigQuery and would like to do some cost optimisation then we would want to do the following:
- Transfer our dataset to a single-region location
- Create a single-region Cloud Storage bucket in the same region with Storage class Archive
- Use a SQL/Python script to export data from our dataset to this bucket daily/monthly.
In this case we can get up to 10 times more cost-effective solution
ORC vs Parquet vs AVRO
These three data formats were designed to store and process large amounts of big data. They are self-describing with schema included meaning we can load data into different nodes and systems will still be able to recognise it. They all work with compression very well which means less storage costs. And they all were designed with parallel computation in mind meaning we can speed up queries by loading them into parallel nodes or disks. Parquet and ORC store data in columns and offer a compression ratio higher than AVRO. BigQuery doesn't support export in ORC format and works only with AVRO, CSV, JSON, PARQUET. However, in BigQuery you can load ORC files easily into a table from Cloud Storage.
Long story short, if you data structure might change over time and you need a schema evolution support then choose AVRO. It will store data in row-based format using JSON to describe the data. It is using binary format to reduce storage size, yet offers less compression than ORC and Parquet. AVRO also offers a faster writing speed and
might be a good choice for data format in source/landing layer where we need to ingest data as a whole file anyway.
In this case AVRO allows faster processing and offers a reasonable compression rate with SNAPPY (still Hadoop splittable).
If you need faster data access for your analytical queries then columnar format might be a better choice. Also if you require a higher compression ratio then ORC and Parquet would suit better.
ORC is usually considered as the best file format option for HIVE, whereas Parquet is considered as the optimal solution across the Hadoop ecosystem.
In fact, Parquet is a default file format for Spark and works better than anything there.
What is splittable?
Splittable means that Hadoop will be able to split data into blocks and send them to mapper instead of processing the file as a whole. This will enable distributed computing and process data in parallel.
Block-level compression, which is implemented in compressing codecs like SNAPPY, allows mappers to read a single file in blocks concurrently even if it is a very big file.
From the data warehouse to cloud storage
Let's create a bucket for our data export
This is a trivial operation if you have gsutil installed. You can create either regional or multi-regional buckets in GCP. Regional buckets are less expensive. However, your dataset must be in the same location as your bucket or at least co-located within the multi region. For example, if your BigQuery dataset is in the US multi-region, the Cloud Storage bucket can be located in the US-CENTRAL1 region, which is within the US.
Very often Firebase projects are being created by default in multi-region locations, i.e. US. Therefore, dataset exports to BigQuery will share the same multi-region location.
In this case you would want to use a multi-region bucket:
gsutil mb -l US gs://events-export-json
gsutil ls -L -b gs://events-export-json
# gs://events-export-json/ :
# Storage class: STANDARD
# Location type: multi-region
# Location constraint: US
Alternatively we can create a bucket located in one of the US regions located inside a multi-region like US
and that would be a much more cost-effective option:
gsutil mb -c regional -l US-CENTRAL1 gs://events-export-json
Delete the bucket
gcloud storage rm --recursive gs://events-export-json/
# run gcloud components update if the previous command didn't work
run
gcloud components updateif the previous command didn't work
Export as JSON
We can use some publicly available Firebase data from firebase-public-project.
For example, Google has a sample dataset for a mobile game app called "Flood It!" (Android, iOS) and you can find it here.
This dataset contains 5.7M events from over 15k users. Open that link above and click Preview. It won't cost anything to run a Preview on any table:
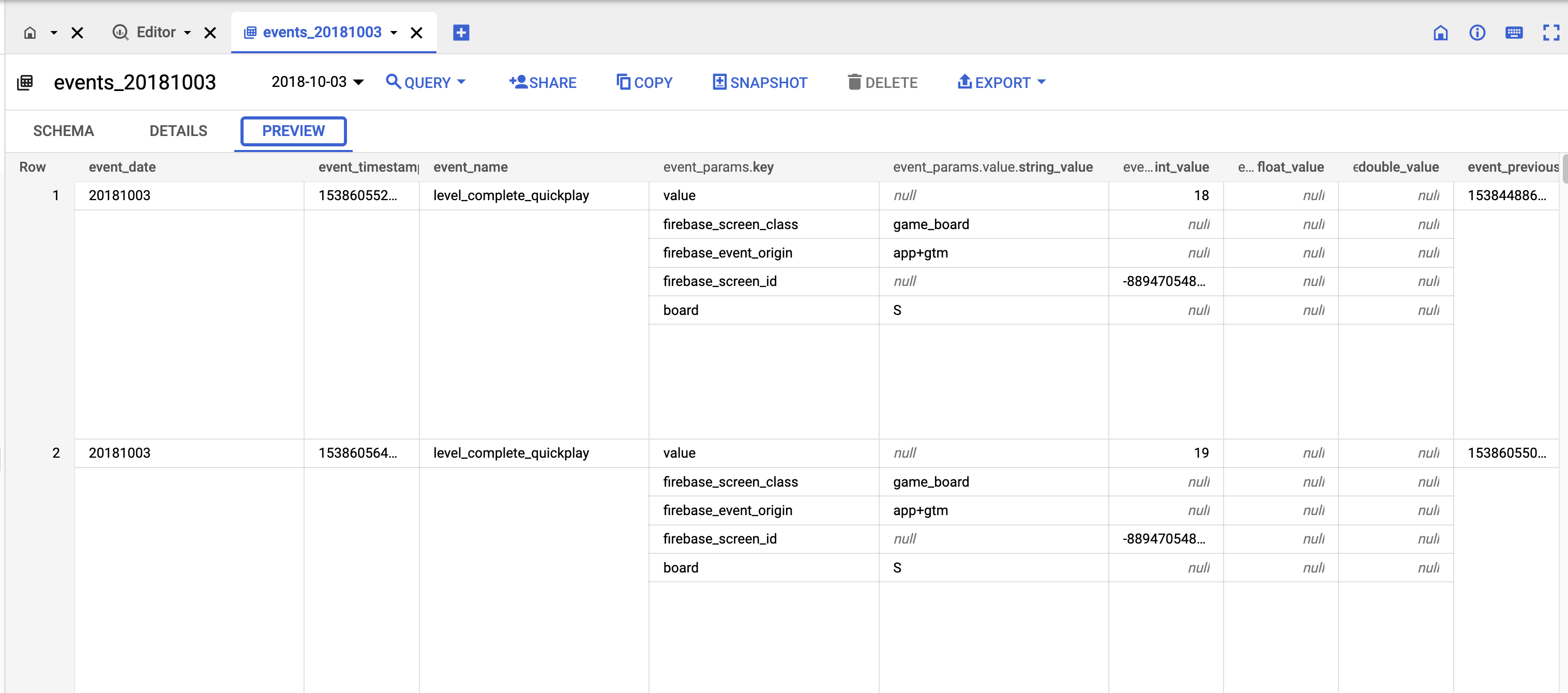
So let's say we want to export the data. Run this SQL in BigQuery:
EXPORT DATA
OPTIONS (
uri = 'gs://events-export-json/public-project/events-*.json',
format = 'JSON',
compression = 'GZIP', -- SNAPPY and DEFLATE not supported for JSON
overwrite = true
)
AS (
SELECT *
FROM `firebase-public-project.analytics_153293282.events_20181003`
);
Let's check the size:
gsutil ls -r -L gs://events-export-json
gsutil du -s -a gs://events-export-json
# 98163921 gs://events-export-json uncompressed
# 2619406 gs://events-export-json if we use GZIP compression
Load data back to BigQuery
We might want to load historical data back to run analytical queries. Even if the table doesn't exist the SQL below will work:
LOAD DATA INTO source.json_external_test
FROM FILES(
format='JSON',
uris = ['gs://events-export-json/*']
)
Export as Parquet
Let's create a new bucket first:
gsutil mb -c regional -l US-CENTRAL1 gs://events-export-parquet
# there is no point in creating a bucket in a multi location. It will just increase storage costs:
# gsutil mb -l US gs://events-export-parquet
There is no point in creating a bucket in a multi location. It will just increase storage costs. Create a co-located single-region instead.
EXPORT DATA
OPTIONS (
uri = 'gs://events-export-parquet/2018/10/02/events-*',
format = 'PARQUET',
compression = 'SNAPPY', -- GZIP, SNAPPY. DEFLATE not supported for parquet.
overwrite = true
)
AS (
SELECT *
FROM `firebase-public-project.analytics_153293282.events_20181002`
);
EXPORT DATA
OPTIONS (
uri = 'gs://events-export-parquet/2018/10/03/events-*',
format = 'PARQUET',
compression = 'GZIP', -- GZIP, SNAPPY. DEFLATE not supported for parquet.
overwrite = true
)
AS (
SELECT *
FROM `firebase-public-project.analytics_153293282.events_20181003`
);
let's check if the data is there:
gsutil ls -r -L gs://events-export-parquet
# gsutil ls -L -b gs://events-export-parquet
Run this to check the size of the bucket:
gsutil du -s -a gs://events-export-parquet
# 2441069 gs://events-export-parquet compressed with SNAPPY
# 4180518 gs://events-export-parquet compressed with GZIP
Tidy up:
gcloud storage rm --recursive gs://events-export-parquet/
Load parquet data into BigQuery
Now we can either load data into the table with predefined autodetected schema or create an external table.
LOAD DATA INTO source.parquet_external_test
FROM FILES(
format='PARQUET',
uris = ['gs://events-export-parquet/*']
)
External tables are a lot slower than standard tables in modern data warehouses and have some well-known limitations:
- For example, we can't modify them with DML statements and data consistency is not guaranteed. Having said that, if the underlying data was changed during the processing we might not get consistent results.
- External tables do not work with clustering and will not let export data from them.
- Will not let us use wildcards to reference table names.
- Have usually a limited number of concurrent queries in modern data warehouses, i.e. 4 in BigQuery.
Create external table using Parquet
CREATE OR REPLACE EXTERNAL TABLE analytics.parquet_external_test OPTIONS (
format = 'PARQUET',
uris = ['gs://events-export-parquet/public-project/events-*.json']
);
select * from analytics.parquet_external_test
;
Extract as AVRO
Let's create a new bucket first:
gsutil mb -c regional -l US-CENTRAL1 gs://events-export-avro
Now let's extract:
EXPORT DATA
OPTIONS (
uri = 'gs://events-export-avro/public-project/events-*',
format = 'AVRO',
compression = 'SNAPPY',
overwrite = true
)
AS (
SELECT *
FROM `firebase-public-project.analytics_153293282.events_20181003`
);
EXPORT DATA
OPTIONS (
uri = 'gs://events-export-avro/public-project/events-*',
format = 'AVRO',
compression = 'DEFLATE',
overwrite = true
)
AS (
SELECT *
FROM `firebase-public-project.analytics_153293282.events_20181003`
);
Let's list the bucket to check the files:
gsutil ls -r -L gs://events-export-avro
# gsutil ls -L -b gs://events-export-avro
Run this to check the size of the bucket:
gsutil du -s -a gs://events-export-avro
# 6252551 gs://events-export-avro compressed with SNAPPY
# 4082993 gs://events-export-avro compressed with DEFLATE
Avro Data Files are always splittable. However, it is not splittable wile using a
DEFLATEcompression (which is similar toGZIP)
Read speed is fairly constant for AVRO with any compression, whereas write speed might vary so you might want to run a few tests. It depends on data.
Tidy up and delete the bucket:
gcloud storage rm --recursive gs://events-export-avro/*
Load data back to BigQuery using AVRO
We might want to load historical data back to run analytical queries. Even if the table doesn't exist the SQL below will work because AVRO format is self-describing (with schema):
LOAD DATA INTO source.avro_external_test
FROM FILES(
format='AVRO',
uris = ['gs://events-export-avro/*']
)
A few things to consider
Parquet and JSON offer the best compression rates. In some data warehouses extract-load of Parquet might change the schema in nested fields. Consider these, for example:
Table schema after loading from parquet will look like that:
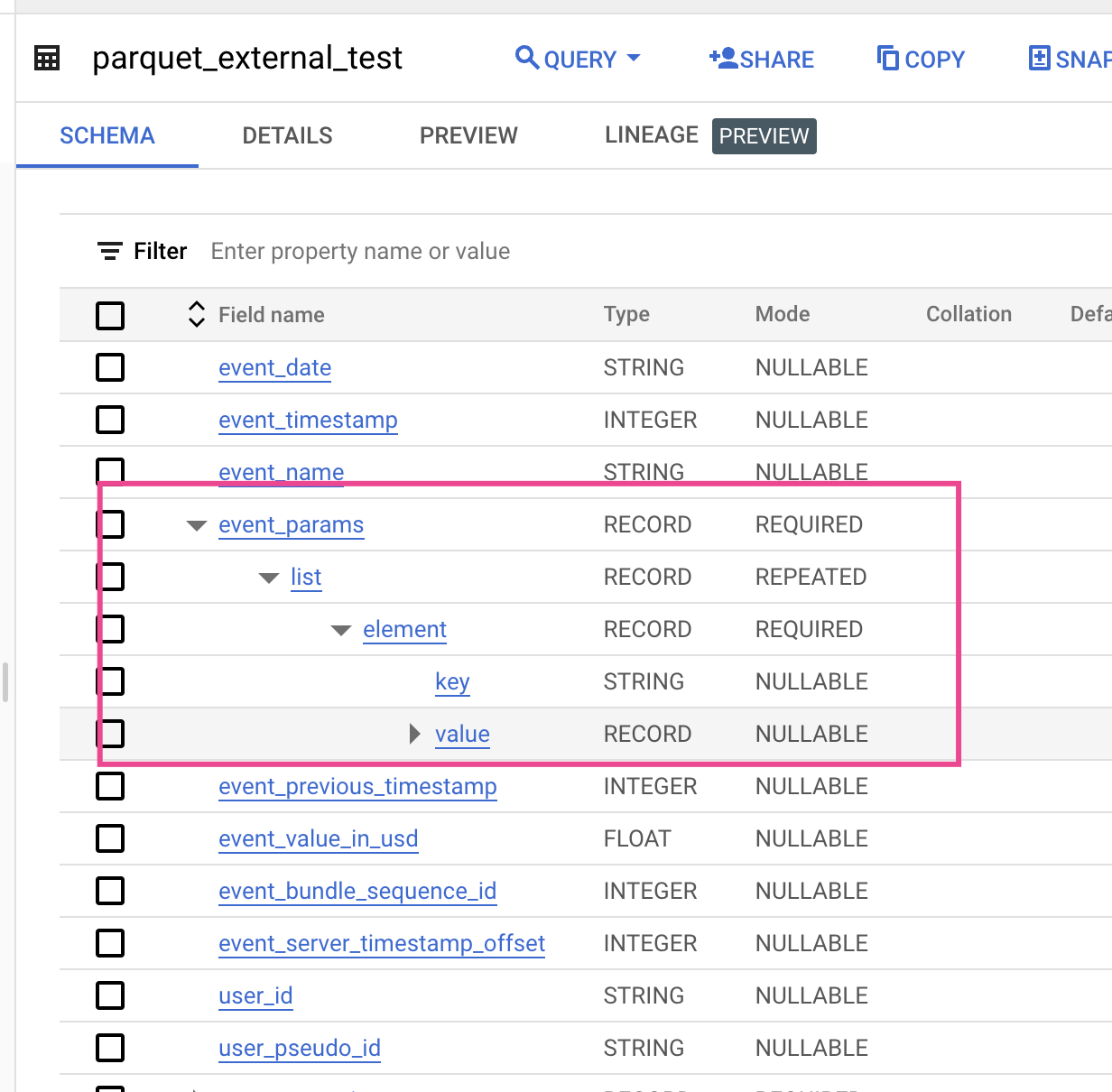
The Parquet schema represents nested data as a group and repeated records as repeated groups.
When in AVRO, JSON and real world Firebase/GA4 scenario it is this:
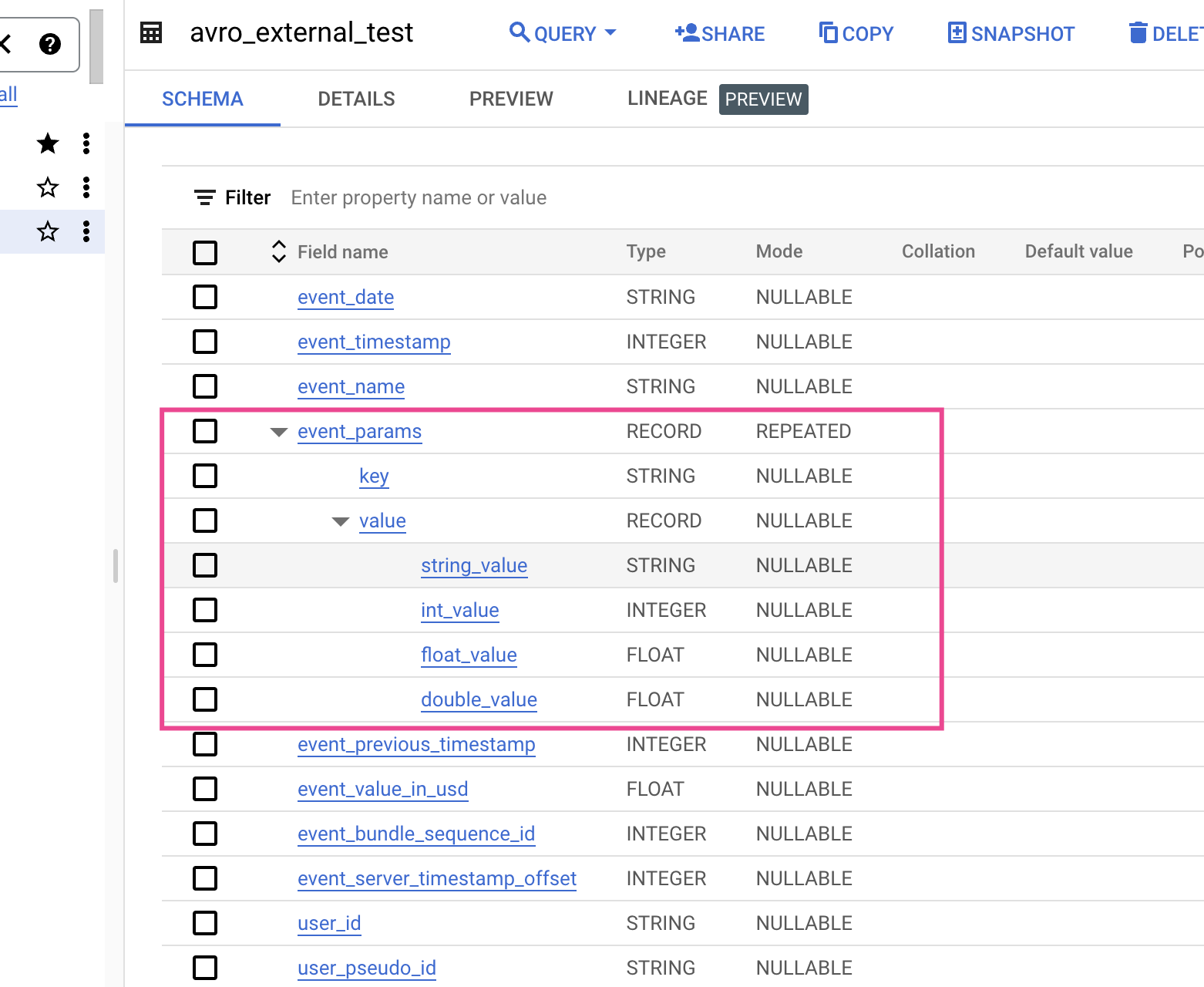
When we extract as JSON symbols like & are converted by using the unicode notation \uNNNN, where N is a hexadecimal digit. For example, profit&loss becomes profit\u0026loss. This unicode conversion was introduced to fix security vulnerabilities. Also INT64 (integer) data types are encoded as JSON strings. This is done to keep 64-bit precision for other systems.
In BigQuery we can export only to Cloud Storage and Google Drive with the file limit of 1Tb. That will split large tables into multiple files.
Wrapping unload with a script
Let's say we would want to upload all historical data older than 12 months to cloud storage and archive it there. If we consider Google Cloud Storage then storage Type ARCHIVE in a single-region bucket is the cheapest.
This will save a lot of money and we can achieve two goals at the same time.
If we need to load it back again at some point then it will be very simple data load operation.
For example, let's create a script to scan our wildcard table with Firebase events and export the data.
Even though BigQuery will not allow us to use a date parameter to get that particular wildcard table we need we can use a SQL script instead
The one I used in this article below can be easily changed to help us to achieve what we need. https://medium.com/towards-data-science/how-to-extract-real-time-intraday-data-from-google-analytics-4-and-firebase-in-bigquery-65c9b859550c
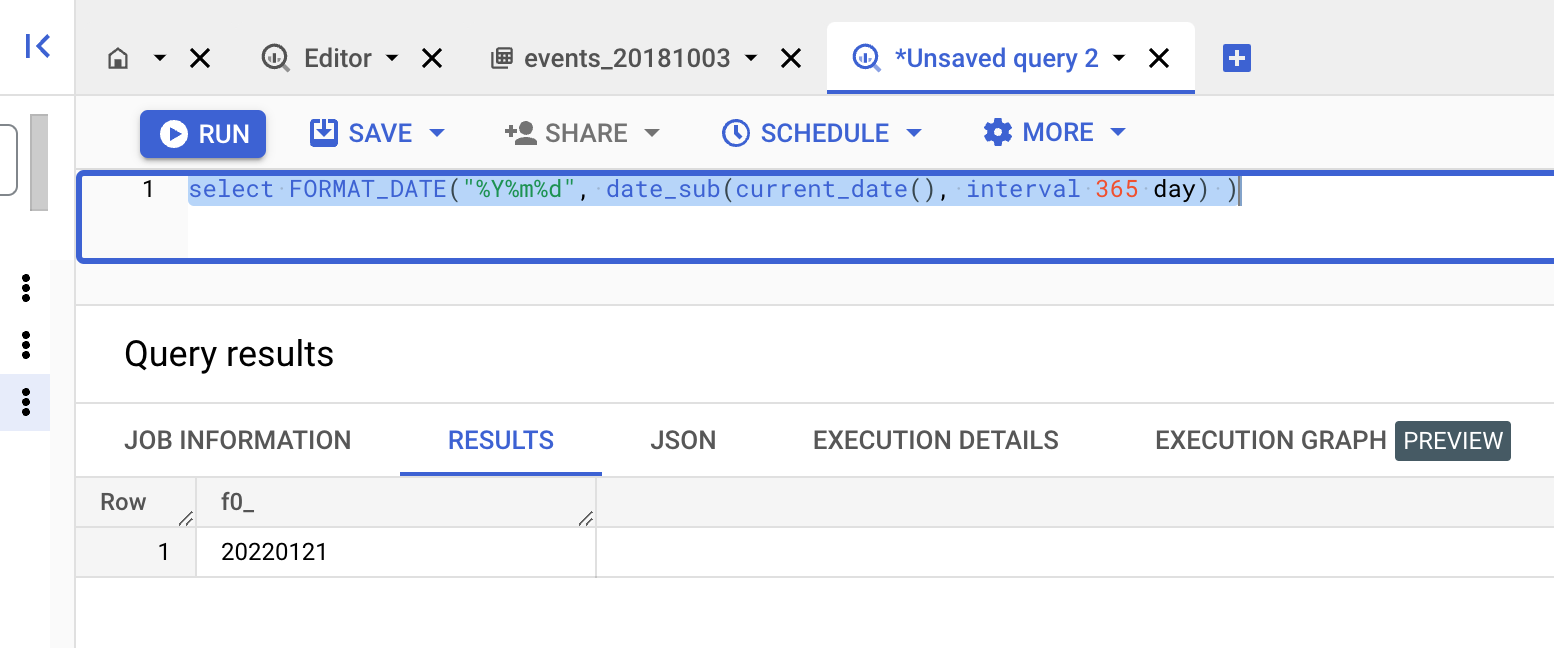
We can get a date like that:
Next, we will create a SQL STRING to execute it within BigQuery as a script
DECLARE select_query STRING;
DECLARE from_query string;
DECLARE results_query string;
DECLARE dt STRING;
DECLARE file_suffix STRING;
DECLARE uri STRING;
SET dt = (select FORMAT_DATE("%Y%m%d", date_sub(date('2019-10-03'), interval 365 day) ));
SET file_suffix = (select FORMAT_DATE("%Y/%m/%d", date_sub(date('2019-10-03'), interval 365 day) ));
SET uri = 'gs://events-export-avro/public-project/' || file_suffix || '/events-*.avro'
;
SET select_query = """
EXPORT DATA
OPTIONS (
uri = @s,
format = 'AVRO',
compression = 'DEFLATE',
overwrite = true
)
AS (
SELECT *
"""
;
SET from_query = CONCAT('FROM `firebase-public-project.analytics_153293282.events_',dt,'`' -- events_20181003
,');'
);
-- Finally execute
EXECUTE IMMEDIATE select_query || from_query using uri as s
--USING dt as a will not work in this: FROM `firebase-public-project.analytics_153293282.events_@a`'
-- It is a well-known fact that BigQuery doesn't support parameters in table names.
;
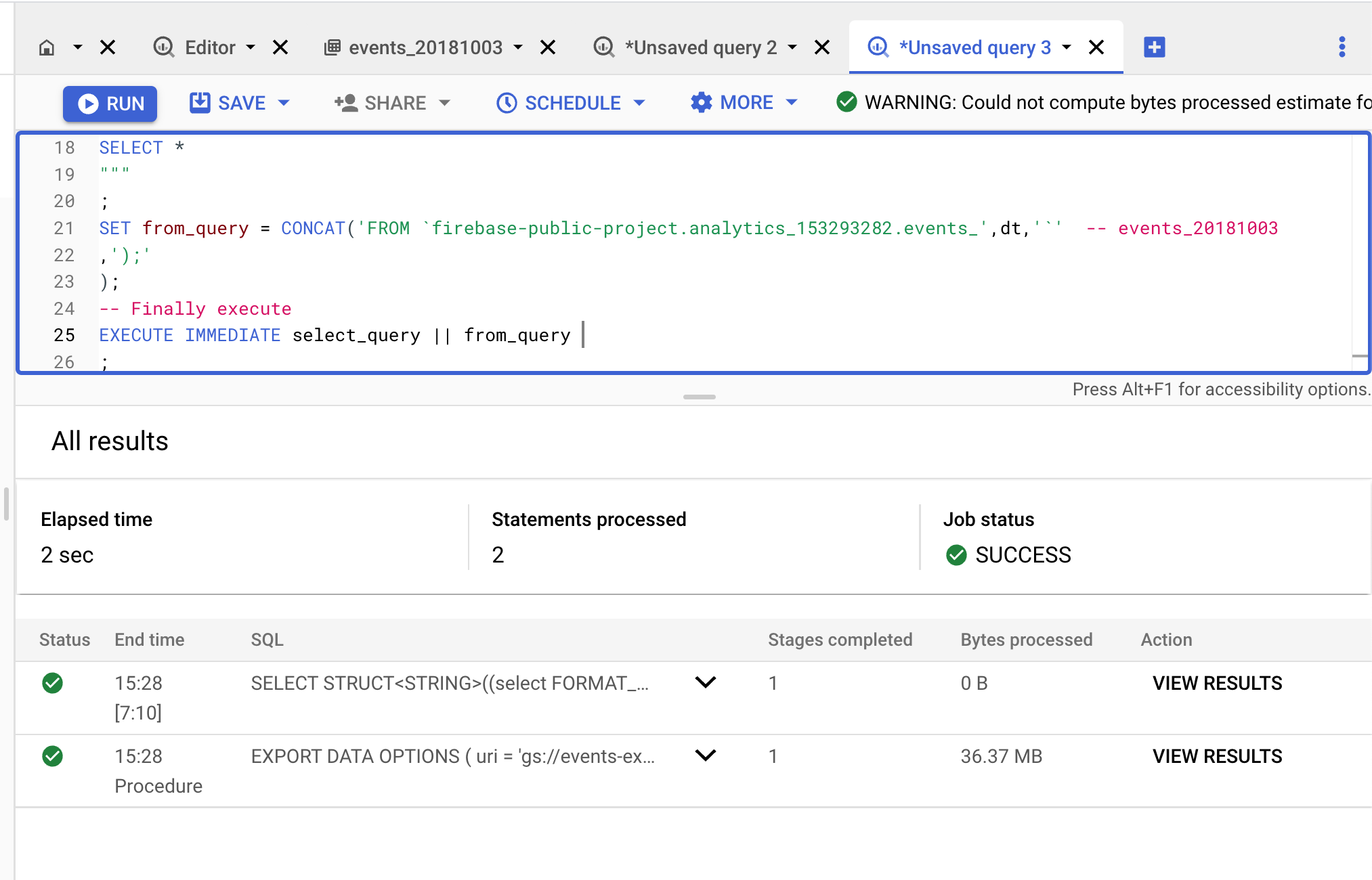
Let's check the data:
gsutil ls -r gs://events-export-avro
# gs://events-export-avro/public-project/2018/10/03/events-000000000000.avro
Partitioned buckets
We might want to create partitioned buckets for data we extract with YYYY/MM/DD pattern, i.e.
gs://events-export-avro/public-project/2018/10/02/*
gs://events-export-avro/public-project/2018/10/03/*
This can be also achieved with scripting
Let's create an array of dates to extract and then LOOP through it.
DECLARE select_query STRING;
DECLARE from_query string;
DECLARE results_query string;
DECLARE dt STRING;
DECLARE file_suffix STRING;
DECLARE uri STRING;
DECLARE dates ARRAY<DATE>;
DECLARE i INT64 DEFAULT 0;
SET dates = GENERATE_DATE_ARRAY('2018-10-01', '2018-10-02', INTERVAL 1 DAY);
SET select_query = """
EXPORT DATA
OPTIONS (
uri = @s,
format = 'AVRO',
compression = 'DEFLATE',
overwrite = true
)
AS (
SELECT *
"""
;
LOOP
SET i = i + 1;
IF i > ARRAY_LENGTH(dates) THEN
LEAVE;
END IF;
SET dt = FORMAT_DATE("%Y%m%d", dates[ORDINAL(i)]);
SET from_query = CONCAT('FROM `firebase-public-project.analytics_153293282.events_',dt,'`' -- events_20181003
,');'
);
SET file_suffix = FORMAT_DATE("%Y/%m/%d", dates[ORDINAL(i)]);
SET uri = 'gs://events-export-avro/public-project/' || file_suffix || '/events-*.avro';
EXECUTE IMMEDIATE select_query || from_query using uri as s;
END LOOP;
After execution we will see the results for our LOOP:
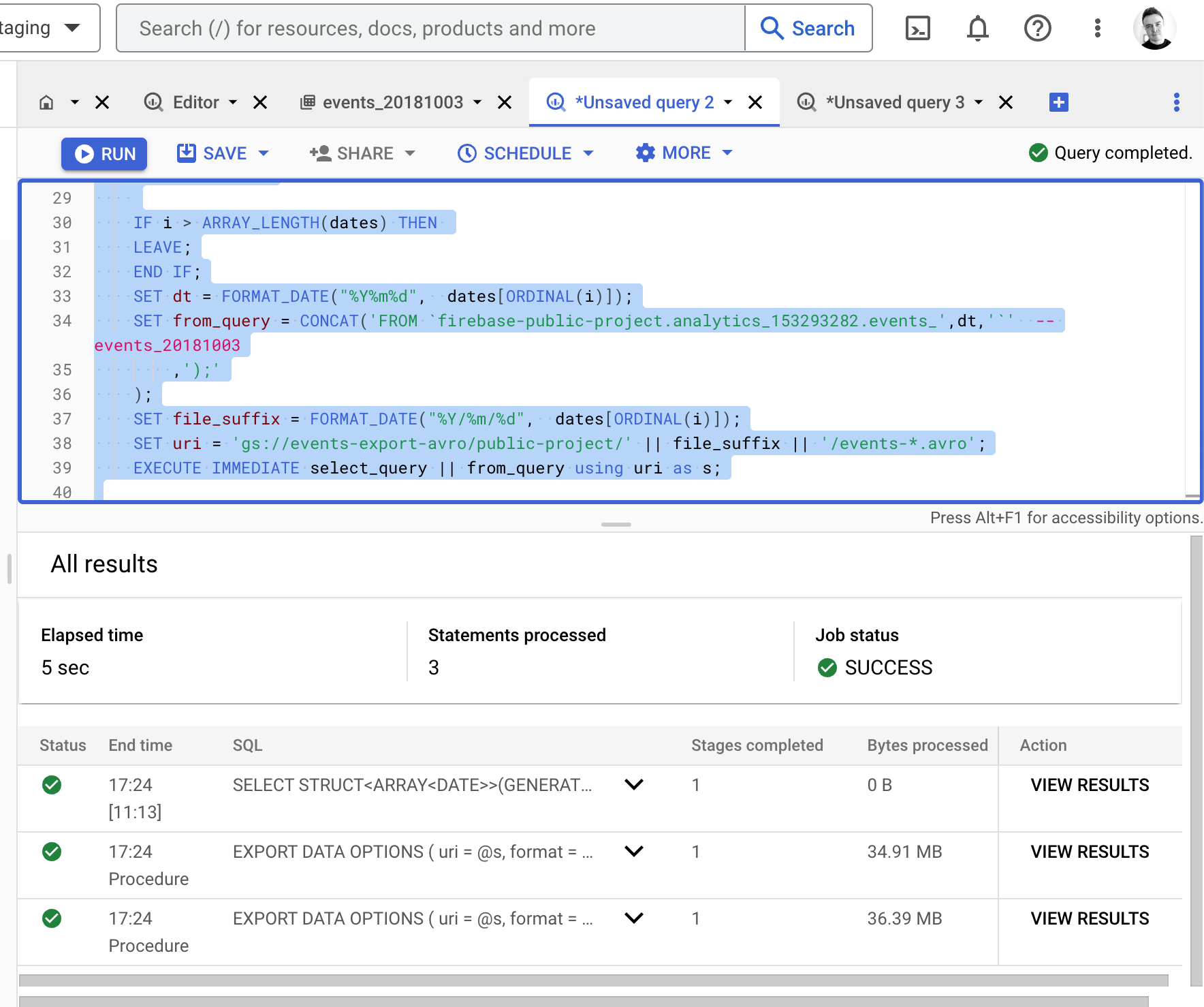
Let's have a look:
gsutil ls -r gs://events-export-avro
# gs://events-export-avro/public-project/2018/10/:
# gs://events-export-avro/public-project/2018/10/01/:
# gs://events-export-avro/public-project/2018/10/01/events-000000000000.avro
# gs://events-export-avro/public-project/2018/10/02/:
# gs://events-export-avro/public-project/2018/10/02/events-000000000000.avro
Hive partitioned layout
In case we need to use externally partitioned data in BigQuery we would want to store data in cloud storage using default Hive partitioning layout. In this case we can create externally partitioned tables on Avro, CSV, JSON, ORC and Parquet files.
Let's change the script to reflect Hive layouts:
- partition keys are always in the same order
- instead of
YYYY/MM/DDwe will use key = value pairs which will be partitioning columns and storage folders at the same time
Example:
gs://events-export-avro/public-project/avro_external_test/dt=2018-10-01/lang=en/partitionKey
gs://events-export-avro/public-project/avro_external_test/dt=2018-10-02/lang=fr/partitionKey
Script:
DECLARE select_query STRING;
DECLARE from_query string;
DECLARE results_query string;
DECLARE dt STRING;
DECLARE file_suffix STRING;
DECLARE uri STRING;
DECLARE dates ARRAY<DATE>;
DECLARE i INT64 DEFAULT 0;
SET dates = GENERATE_DATE_ARRAY('2018-10-01', '2018-10-02', INTERVAL 1 DAY);
SET select_query = """
EXPORT DATA
OPTIONS (
uri = @s,
format = 'AVRO',
compression = 'DEFLATE',
overwrite = true
)
AS (
SELECT *
"""
;
LOOP
SET i = i + 1;
IF i > ARRAY_LENGTH(dates) THEN
LEAVE;
END IF;
SET dt = FORMAT_DATE("%Y%m%d", dates[ORDINAL(i)]);
SET from_query = CONCAT('FROM `firebase-public-project.analytics_153293282.events_',dt,'`' -- events_20181003
,');'
);
SET file_suffix = FORMAT_DATE("dt=%Y-%m-%d", dates[ORDINAL(i)]);
SET uri = 'gs://events-export-avro/public-project/avro_external_test/' || file_suffix || '/lang=fr/partitionKey/events-*.avro';
EXECUTE IMMEDIATE select_query || from_query using uri as s;
END LOOP;
External custom hive-partitioned table:
CREATE OR REPLACE EXTERNAL TABLE source.custom_hive_partitioned_table
WITH PARTITION COLUMNS (
dt STRING, -- column order must match the external path
lang STRING)
OPTIONS (
uris = ['gs://events-export-avro/public-project/avro_external_test/*'],
format = 'AVRO',
hive_partition_uri_prefix = 'gs://events-export-avro/public-project/avro_external_test',
require_hive_partition_filter = false);
Conclusion
With the collection of code snippets from this article we can play around, export the data and run some tests on file formats and compression types.
By unloading the data that is no longer needed in OLAP pipelines, we can optimise the storage by reducing the costs. If our strategy is to save as much money as possible and availability of historical data is not a priority, then this approach is the way to go.
Unloading historical raw event data can decrease storage costs 10 times down.
Every format has its own benefits and compression types and it might be tough to figure out which one is better than the other.
When we need a better compression ratio then ORC or Parquet would suit better. It actually depends on which tool we are going to use to run analytical queries on our data. ORC is better optimised for HIVE and Pig framework workloads, whereas Parquet is a default file format for Spark.
GZIP, DEFLATE and other non-splittable compression types would suit better for cold storage with infrequent access to data.
When all fields must be accessible, row-based storage makes AVRO would be the preferable option. It also offers more advanced schema evolution support and is more efficient in queries with write-intensive, big data operations. Therefore, it suits better for data loading from the landing area of our data platform.
Recommended read
1. https://cloud.google.com/bigquery/docs/external-data-cloud-storage
3. https://cloud.google.com/bigquery/docs/external-tables#external_table_limitations
4. https://cloud.google.com/bigquery/docs/hive-partitioned-queries
5. https://cloud.google.com/storage/docs/locations
7. https://cloud.google.com/bigquery/docs/exporting-data
8. https://cloud.google.com/bigquery/docs/hive-partitioned-queries
9. https://cloud.google.com/bigquery/docs/omni-aws-create-connection
11. https://cloud.google.com/storage/docs/gsutil/commands/du
12. https://cloud.google.com/bigquery/docs/managing-partitioned-table-data#exporting_table_data
13. https://cloud.google.com/bigquery/docs/managing-partitioned-table-data#exporting_table_data
15. https://cwiki.apache.org/confluence/display/hive/languagemanual+orc
16. https://parquet.apache.org/


Mike
Mike is a Machine Learning Engineer / Python / Java Script Full stack dev / Middle shelf tequila connoisseur and accomplished napper. Stay tuned, read me on Medium https://medium.com/@mshakhomirov/membership and receive my unique content.
Comments