How to automate data loading into BigQuery with Serverless and Node.js
File formats, yaml pipe definitions and triggers for your simple and reliable data ingestion manager.
Project outline
You will find how to:
- Automate data loading into your data warehouse and build a data loading service with Serverless (AWS Lambda)
- Add various file format support and load different files, i.e. JSON, CSV, AVRO, PARQUET.
- Add DynamoDB table to store ingestion logs and check if a file was already ingested
- Add data transformation features, i.e. in case you might want to mask some sensitive data or change formatting on the fly.
- Load multiple files at once
- Deploy your data loading service using Infrastructure as code, i.e. AWS Cloudformation
- How to load compressed files into BigQuery
- How to monitor data loading errors
About the idea
BUILDING A DATA WAREHOUSE: LOADING DATA
Usually you would want to put your data warehouse solution (BigQuery, Snowflake or any other) in the center of the diagramme.
- Connect any external data source with ease, i.e. setup a pipe to get data from some arbitrary API, i.e. like I wrote previously about PayPal here and save to the Cloud.
- Load data into BigQuery
- Transform data and create documented data pipelines with Git, CI/CD. For example, with Dataform or dbt.
- Simplify and automate deployment with Cloudformation or Terraform (Infrastructure as a code)
- Create BI reports with Google Data Studio (for example, revenue reconciliation, etc.) or any other Business Intelligence solution. Check the image below to see other options.
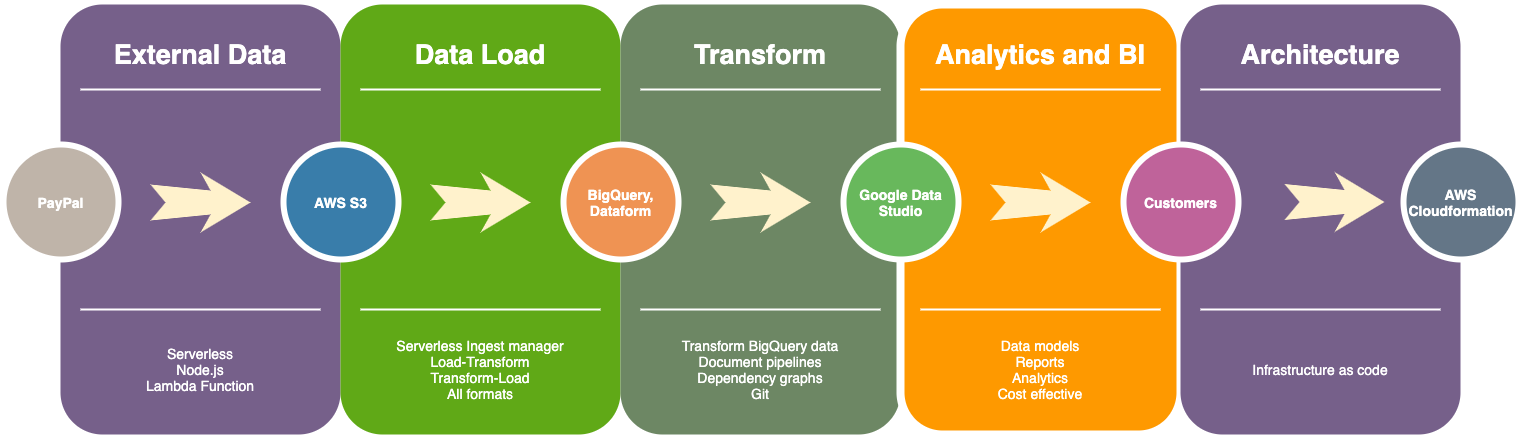
MODERN DATA STACK TOOLS (not a complete list of course):
- Ingestion: Fivetran, Stitch
- Warehousing: Snowflake, Bigquery, Redshift
- Transformation: dbt, Dataform, APIs.
- BI: Looker, Mode, Periscope, Chartio, Metabase, Redash

Talking about data extraction and ingestion you would want to use paid and managed tools like Fivetran or Stitch to extract data from any arbitrary data sources (i.e. Payment merchant providers, Exchange rates, Geocoding databases, etc.) but if you follow this tutorial you will become totally capable of doing it yourself.
Scenario
Imagine you are a Data Engineer and you are working on a project connecting various data sources into your data warehouse in BigQuery. Your company is a mobile game development studio and have various products being sold on both platforms, IOS and ANDROID.
YOUR STACK
Your dev stack is hybrid and includes AWS and GCP. Your team use Node.js a lot. Data science team use Python but server and client data pipelines are being created using Node. Your data stack is modern, event-driven and data intensive. Data warehouse solution must be cost-effective and flexible enough so you could add any data source you need. It must be able to scale easily to meet growing data you have.
THE TASK
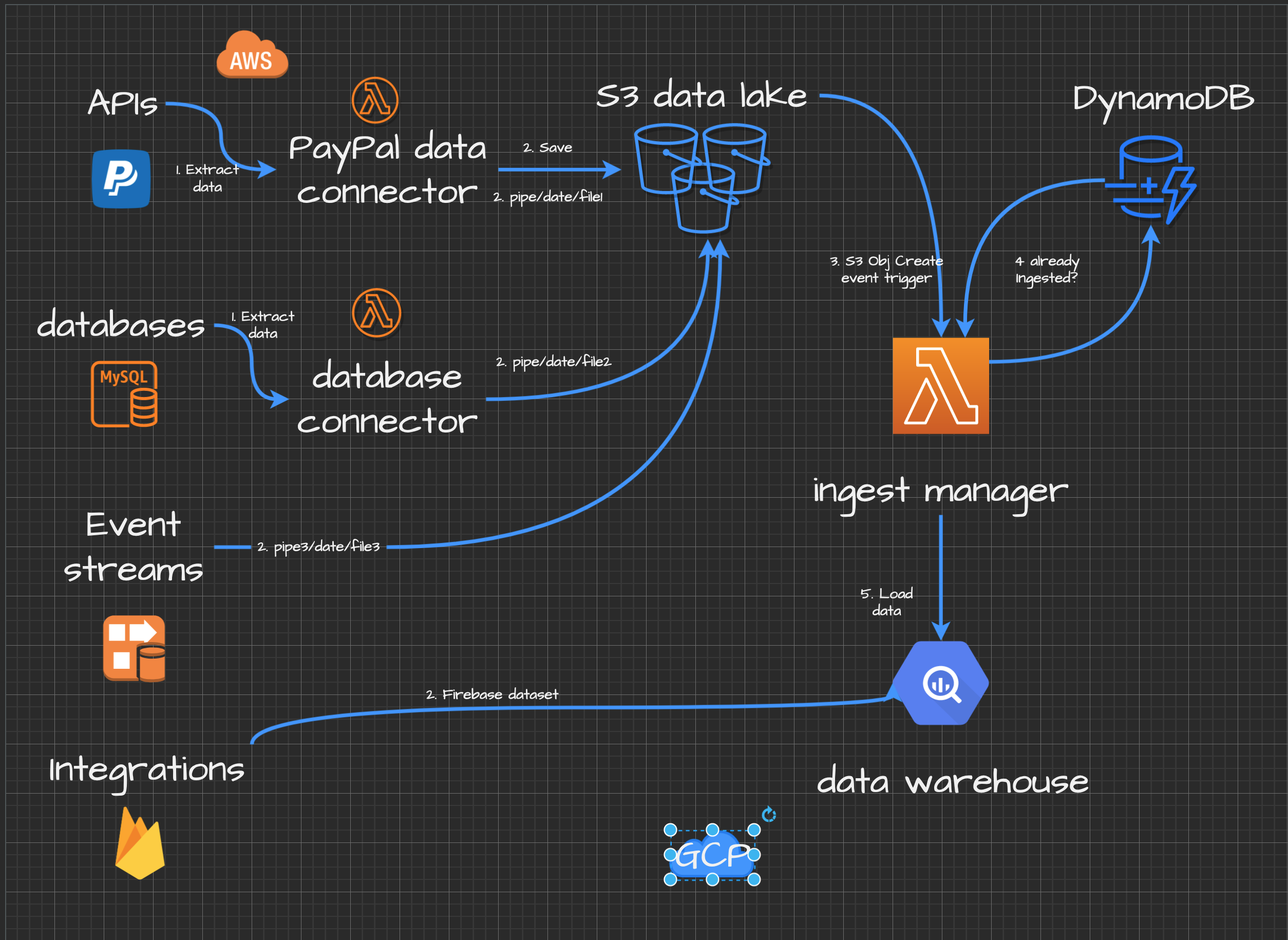
All data comes from files from varioius data surces, i.e. databases, kinesis firehose streams and various notification services. It is being stored to your Cloud Datalake in different formats (CSV, JSON, PARQUET, etc.).
As a data engineer you were tasked to automate data loading process into your BigQuery data warehouse. You have many arbitrary data sources and pipes feeding files into your AWS S3 data lake.
Now you need a reliable service to manage file formats, decide which table to upload into and monitor the overall process. You decided to use AWS Lambda functions and Node.js for this task.
Your micro service application logic:
- Your data connectors extract data from some data source (could be arbitrary, i.e. PayPal)
- Files are being saved to S3 datalake.
- Data ingestion will be triggered when new files land in your S3 data bucket.
- The service will process the files and prepare it for BigQuery so it could insert it into tables. The service will decide which table to insert into.
- The service will check if the file has been already ingested to prevent duplicates. You will use AWS DynamDB to keep data loading records.
- Catch data ingestion errors and save files in your data error bucket for further investigation.
- You can now transform your data in data warehouse.
- Monitor your data loading process with notifications. If there are any errors you will receive an email.
Prerequisites, Libraries and setup
TOOLS
- Node.js and Node package manager installed
- Basic understanding of cloud computing (Amazon Web Services account), AWS CLI and AWS SDK
- Google BigQuery and a service account to authenticate your service.
- Shell (Command line interface) commands and scripting (Advanced).
TECHNIQUES
- Understanding of REST APIs.
- Good knowledge of Node.JS (intermediate). You will create a Lambda Function.
- You must understand Node.JS basic concepts, i.e. async funcitons, Node packages and how the code works.
- basic debugging (consoles, print statements)
- loops: i.e. for
- branches: if, if/else, switches
- Shell commands and scripting as you would want to deploy your Lambda using AWS CLI from command line and be able to test it locally.
Let's begin
Step 1. How to build a data loading service with Serverless (AWS Lambda) and automate data loading into your data warehouse
Create a new S3 bucket for your data lake
Replace your-bigquery-project-name.test.aws with your bucket name and run from command line, i.e. if you use AWS CLI aws s3 mb s3://bq-shakhomirov.bigquery.aws.
You will see something like: $ make_bucket: bq-shakhomirov.bigquery.aws confirming bucket was created.
Read Read AWS S3 documentation
Upload the datasets from ./data to your newly created S3 bucket:
$ cd data
$ aws s3 cp ./data/payment_transaction s3://bq-shakhomirov.bigquery.aws/payment_transaction
$ aws s3 cp ./data/paypal_transaction s3://bq-shakhomirov.bigquery.aws/paypal_transaction
Create an empty AWS Lambda function (Node.js).
You can do it using AWS web console or AWS CLI. It is up to you and initialise your Node.js app locally.
Your microservice folder structure must look like this:
Where bq-shakhomirov-service-account-credentials.json would be your BigQuery service account credentials.
Grant your service a permission to read data from data lake bucket
You would want to read your dataset files from your S3 data bucket and then load that data into your BigQuery data warehouse. So you will need to grant your Lambda function S3 access to your bucket like so:
You can find more about how to create roles in AWS docs here. I will provide an example of how to do it with AWS Cloudformation stack later.
Install required dependecies
Install required node modules and libraries as in ./package.json. You will need:
- "aws-sdk": "2.804.0" to access S3 bucket with data
- "run-local-lambda": "1.1.1" to test nad run your Lamdba locally
- "@google-cloud/bigquery": "^5.7.0" to ingest data
- "moment": "^2.24.0" to process dates and to create relevant
file names/BigQuery jobIds
Make sure you can run it locally. The idea is to kind of emulate an event (S3 object create event) by running npm run local command from your command line.
Install "run-local-lambda": "1.1.1" to test nad run your Lamdba locally.
Your ./package.json must look like this:
Run npm i in your command line and it will install the dependencies.
app.js
In your ./app.js add async processEvent() function to handle the events.
Your ./app.js would look like:
Where ./config.json is your service configuration file.
I prefer using yaml instead byt that's just a matter of taste. In the end you will find a solution using
npm configbased on yaml files for your Lambda.
Example of your ./config.json could have live and staging environment setup and looks like that:
With config file you define the logic, table names and how to choose relevant files for these tables.
Using this config file above your data loading service will try to match name key with relevant file name fileKey. If it finds a match in S3 event then it will start loading data.
BigQuery credentials file
./bq-shakhomirov-b86071c11c27.json is an example of BigQuery credentials file. You will need this Service account credentials file to authenticate your micro service with Google so it could actually do something.
Read more about Service Account authentication here.
Just download it from your Google Cloud Platform account and add to your app folder.
It would look like that:
How to check if a table exists in BigQuery
You would want to do it before loading the data. Add this function into your ./app.js file inside processEvent(). If table doesn't exist it will use a schema from config file and create one.
This function will create a table with schema from config file within the dataset called source. It shoud come from ./config.json too but this is just an example.
How to stream load (insert row by row) a JSON file into BigQuery
This would be a row by row insert operation. When one row doesn't comply with the schema then only that particular row will not be inserted in comparison with batch inserts in BigQuery (one row fails schema validation - all file upload fails).
You would want to add a function:
This is just an example where JSON data already declared (you don't need to read it from local file or from Cloud Storage) and table has been already created. simple_transaction is a simple table with just 3 columns: transaction_id, user_id and dt defined in ./config.json schema for table called simple_transaction. Try it and it will insert data row by row into BigQuery table.
You can slightly adjust this function to read data from a local file for example and it will process New line delimited file ./data/simple_transaction and create a load job operation istead of writeStream we used before.
How to load JSON new line delimited data from AWS S3
If your data is New LIne Delimited JSON (BigQuery's natural way of loading JSON data) then you would need a function like this one below. This function will do the following:
- Create a readStream and Read file from AWS S3
- Use JSONStream module to parse data in JSON file
- Create a batch load job in BigQuery.
Add this one to your ./app.js and try npm run test. Modify ./test/data.json so it's object.key = 'simple_transaction:
Your file contents should look like that
So what's the difference between BigQuery stream insert and batch insert operations?
It is still one job (not BigQuery streaming insert like we did above) but architecture wise it is very memory efficient and is free. You just need NOT to exceed the quota for batch job per table per day. I wrote before how to monitor batch load job operations in BigQuery here https://towardsdatascience.com/monitoring-your-bigquery-costs-and-reports-usage-with-data-studio-b77819ffd9fa
BigQuery streaming is good but might incure higher costs. I would recommend to use batch insert instead where it's possible. It has a daily quota of 2000 inserts per table but you can insert a whole file in one go. Streaming insert is not so cheap, $0.05 per GB that's $50 for 1TB. Streaming insert is the recommended way to import data, as it's scalable. However it doesn't make a big difference if your files in data lake are relatively small which usually happens when using data streams, i.e. Kinesis or Kafka. Read more about BigQuery quotas and limits here
How to load CSV data into BigQuery table with Node.js and AWS Lambda micro service
You would want to add a function which reads data from S3 object and uploads it into BigQuery table as CSV:
This is an example of reading a CSV file from S3, Ideally you would want to do it in Node.js streaming mode saving your memory and not reading the whole file into memory. It creates a readable stream which then flows into stream writable into BigQuery.
Partial solution
Here is the app.js for this project. It's a simplified application. Copy this file and use it to develop your solution.
You will have to create your own BigQuery service account credentials, i.e. like I did to download ./bq-shakhomirov-b86071c11c27.json and create your own ./config.json to define table schemas and app environments.
This app does the following:
- When you run
$npm run testit would use a payload from./test/data.jsondescribing S3 file location (check the scripts in./package.json) - Then it will get the settings from
./config.json, i.e. credentials location, etc. and authenticate with BigQuery API - It will loop through the table described in
./config.jsontrying to find a match inside the payload. Payload in this case emulates S3 Object created event. - If a match found the service will try to get that file from S3 and load data from it into a relevant BigQuery table.
- It will check if table exists and IF NOT then it will create a new one using a schema from
./config.json
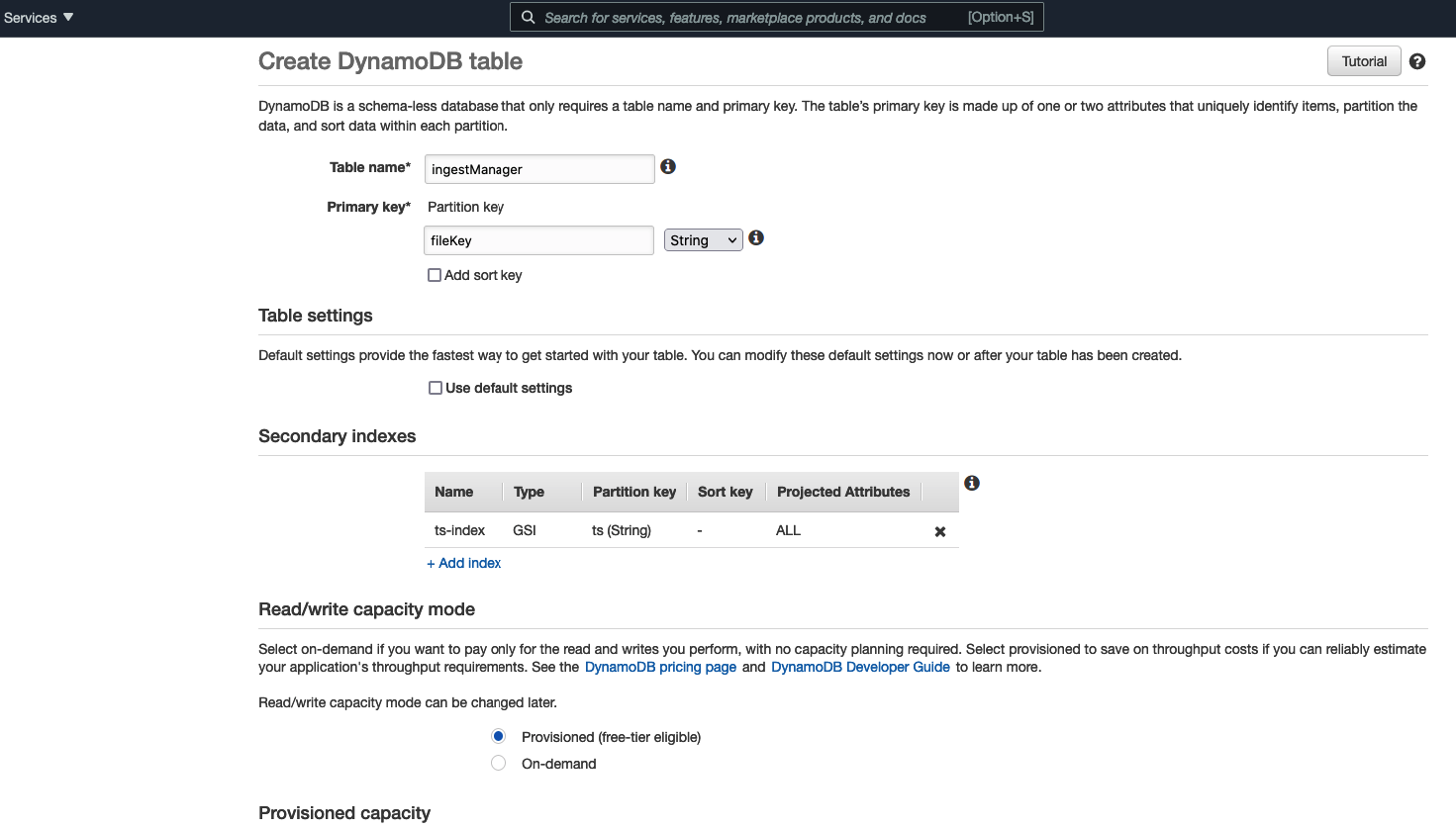
Add DynamoDB to keep data ingestion records
If you need to handle duplication attempts for your load jobs then you probably would want to create a new DynamoDB table and keep records of ingested files.
Then you would consider adding this snippet to your application in ./app.js:
If you then add something like await logSuccessfulEvent(sourceBucket, fileKey, now.format('YYYY-MM-DDTHH:mm:ss')); it would start logging successfully ingested files but you need to create a table first:
Go to AWS Console :
Create a table called
ingestManagerfor successfully ingested files.Add permissions to access Dynamo table to your Lambda.
Add
logSuccessfulEventfunction to handlesuccessfullevents to./app.jsfile:
As a result you should see a new ingestion record created:
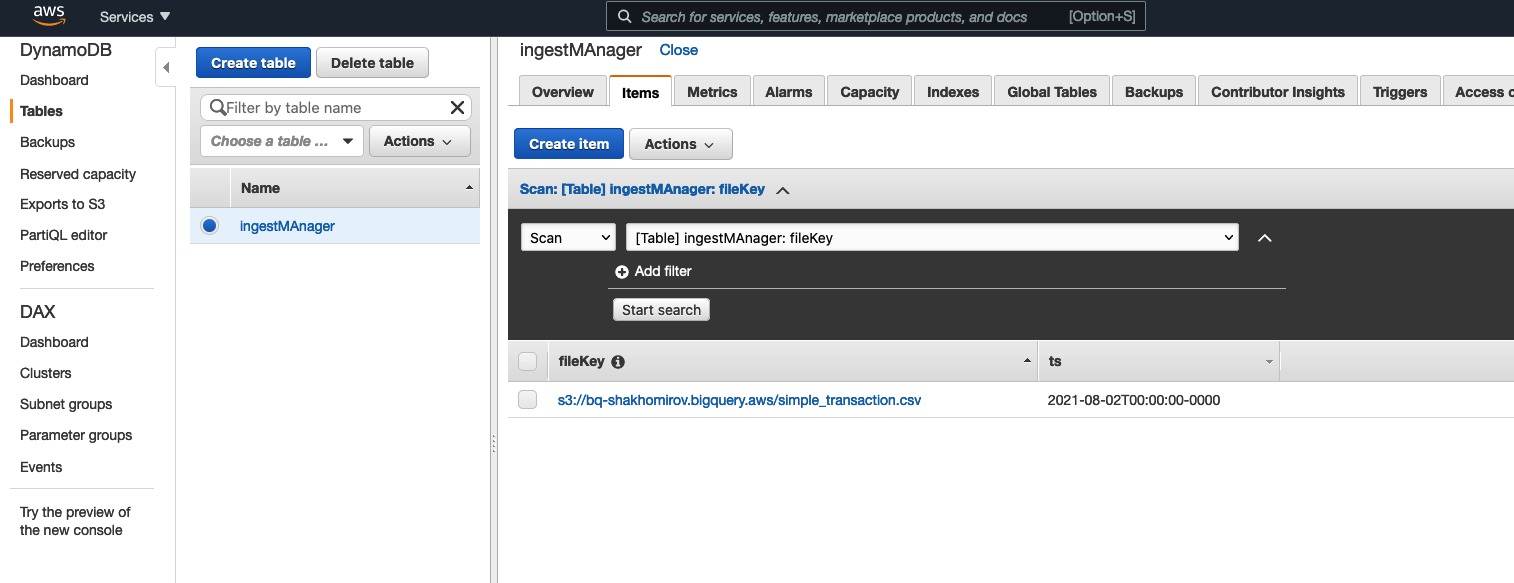
Now you would want to add a new function. Let's call it checkAlreadyIngested().
This function will check your data loading pipeline for any duplication attempts and prevent those.
Just make sure it's wrapped with try, catch block.
How to monitor errors and duplication attempts in your data loading service for BigQuery
... or any other data warehouse really.
You would probably want to receive a notification each time your AWs Lambda errors.
Create an AlarmNotificationTopic with Simple Notification Service (SNS) to receive notifications by email in case of any ingestion errors.
When you created your Lambda and attached the policy it must have created a LogGroupName:
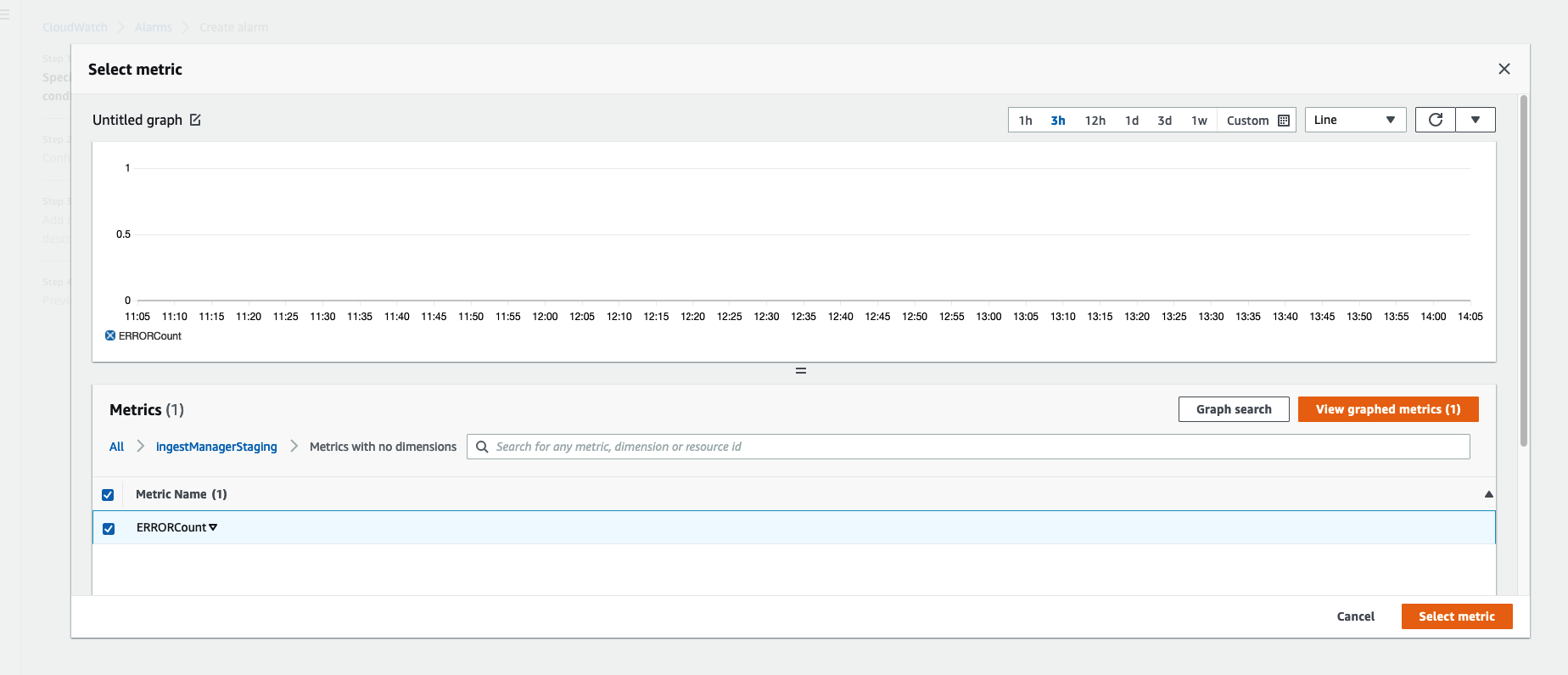
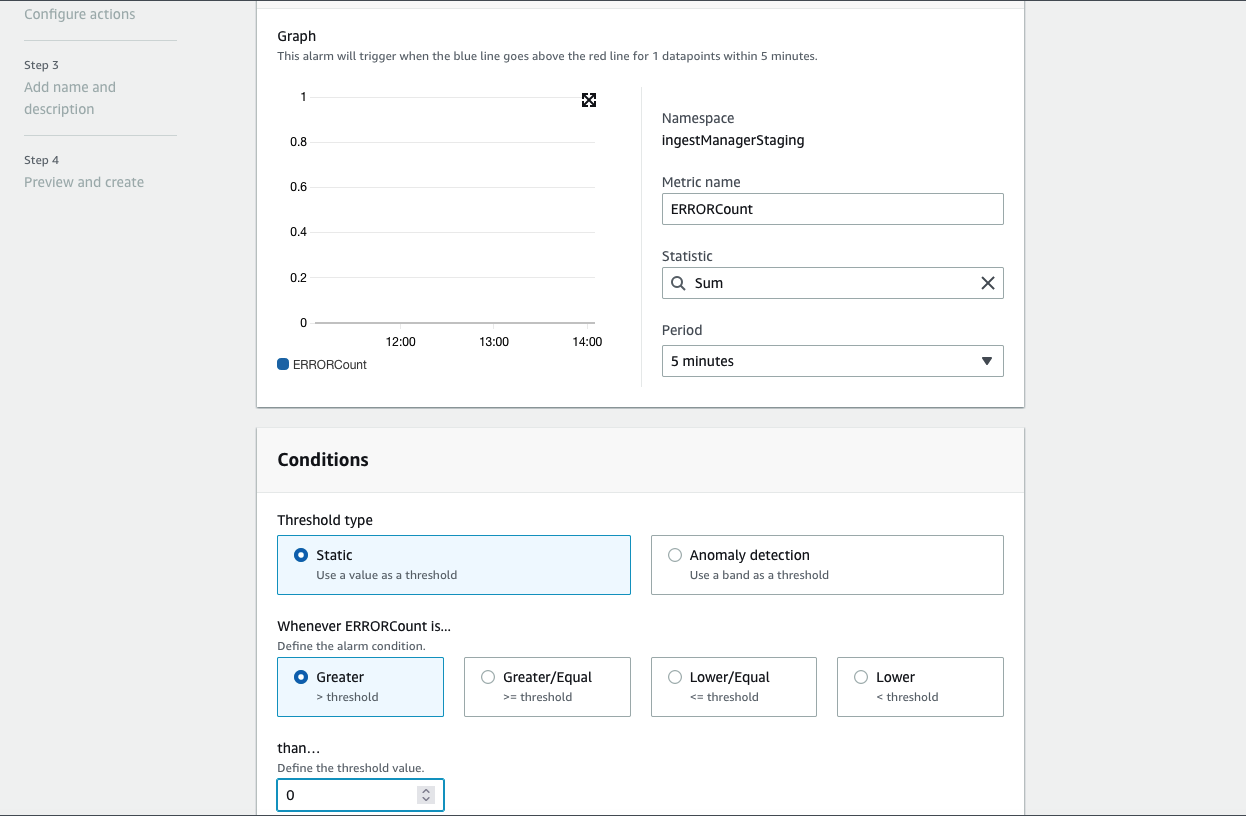
/aws/lambda/ingestManageror something like that. Use it to create ERRORMetricFilter where ERROR count > 0. For example, my Log group looks like this: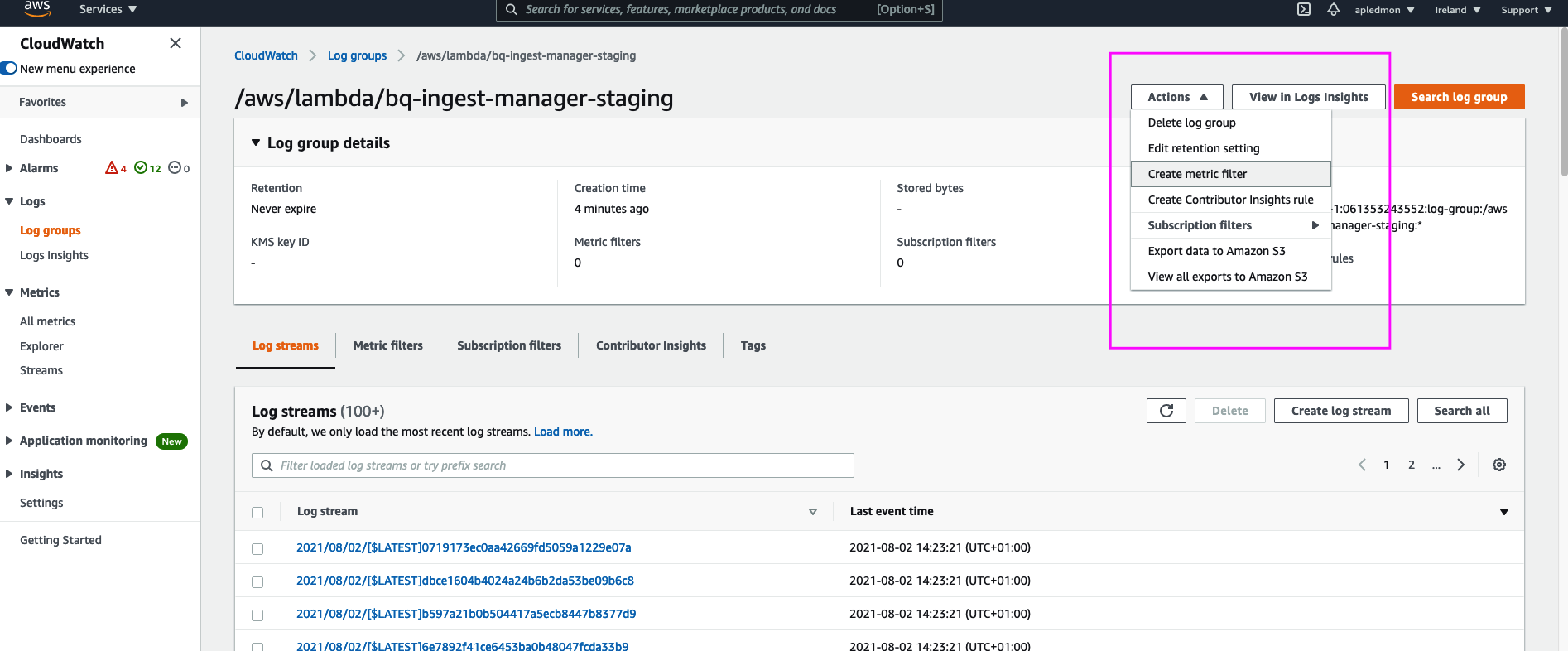
Use the following pattern to create an ERRORMetricFilter: FilterPattern: 'ERROR' Call it
ingestManagerStagingMetricFilter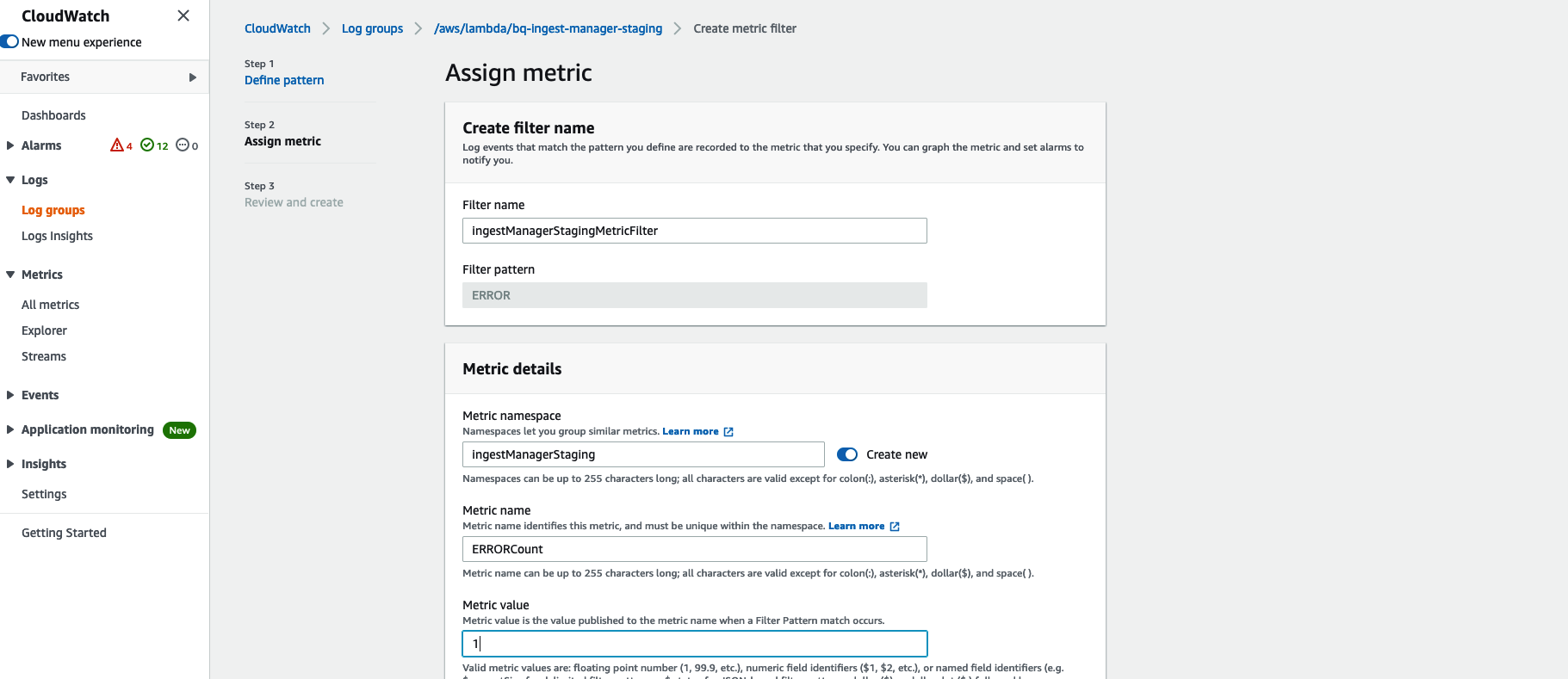
Now go to
SNSand create your alarm topic: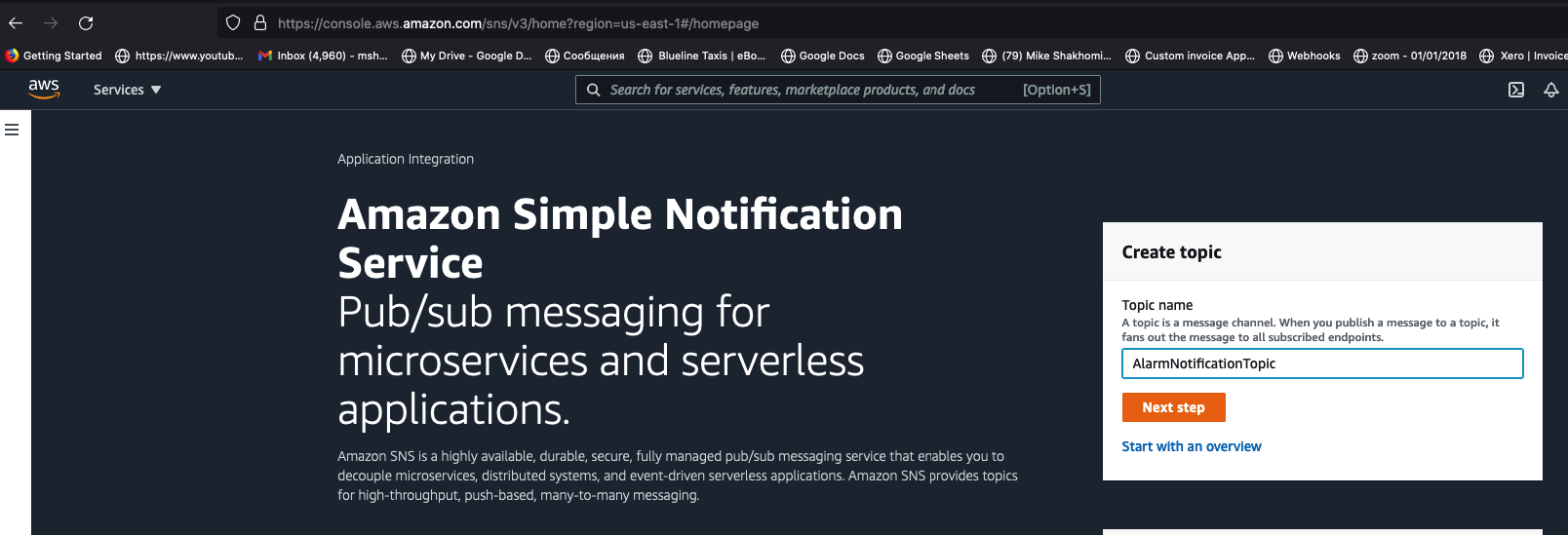
Click create subscription and enter your email:
Finally create ERRORMetricAlarm with action to trigger an alarm when number ERROR greater than 5 for 5 consecutive minutes. It should send notification to your SNS topic.
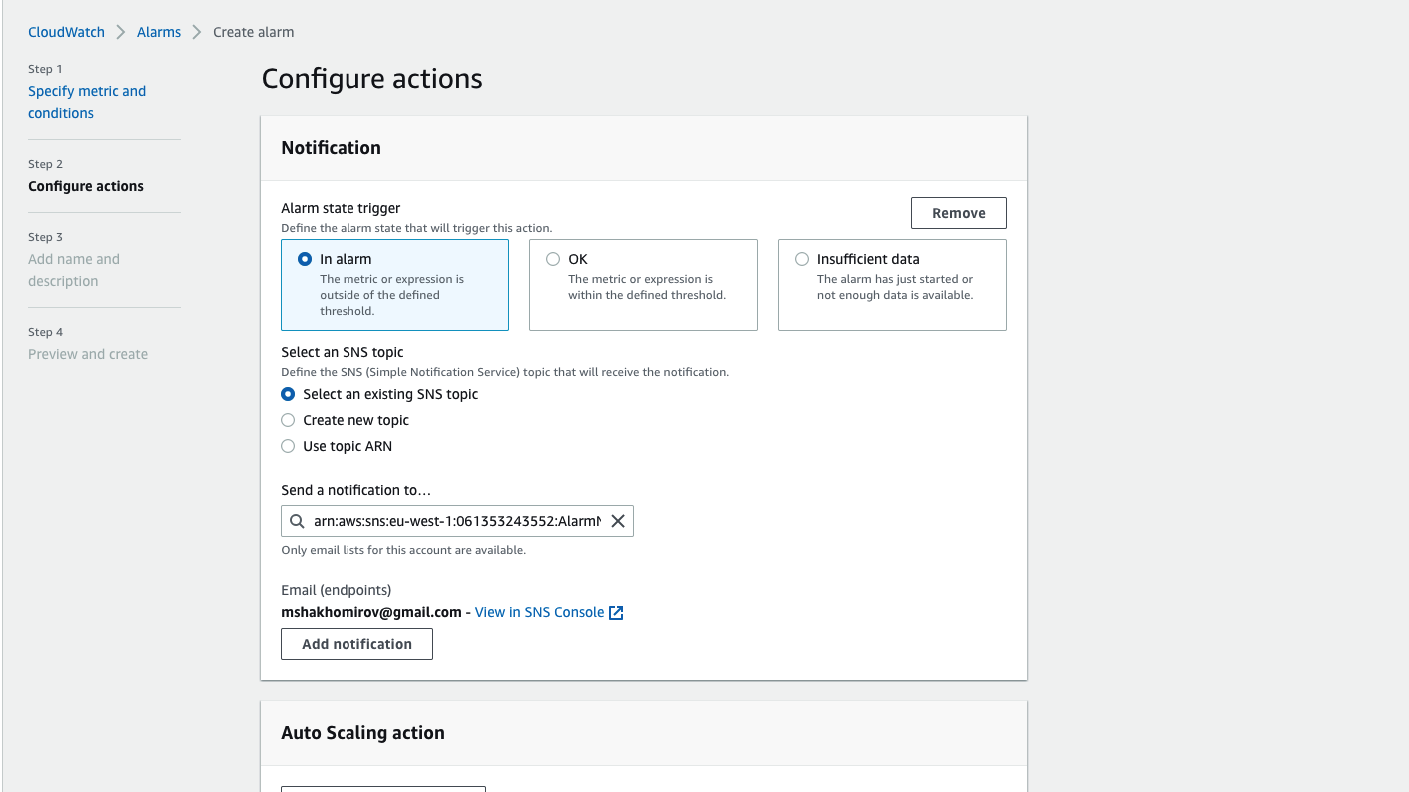
Choose where to send notification if encountered an alarm:
Desired outcom would be a notification in case of ingest manager error:
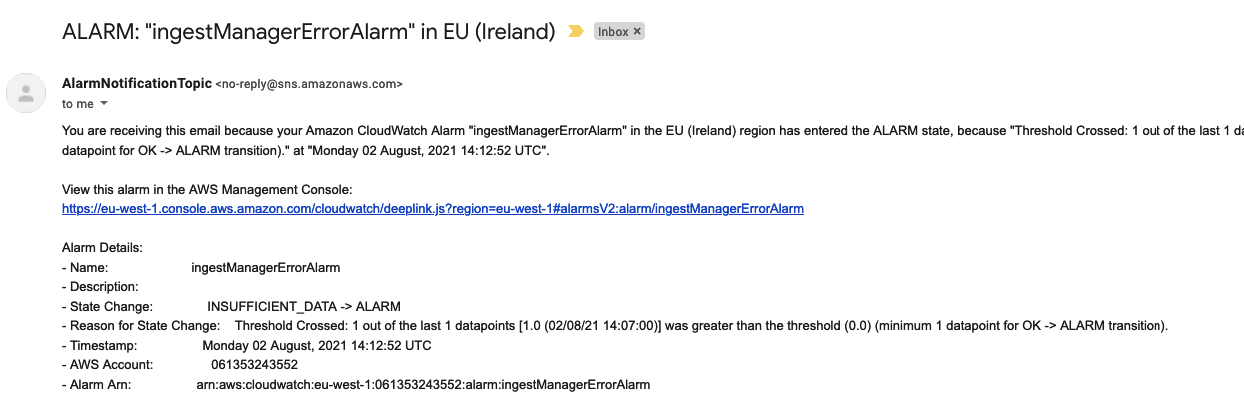
Ideally you would want to use something like AWS Cloudformation to manage your Infrastructure as code.
Example stack file can be found in the Github repository for this tutorial.
How to transform data in original data lake files and prepare it for BigQuery
Naturally BigQuery works either with New line delimited JSON or other formats which were correctly formed already. So if you are loading ndJSON then it should be new line delimited before that:
Now imagine you have another service extracting data from MySQL database and it's output looks like an array of JSON objects: [{...},{...},{...}]. These individual JSON objects could be deeply nested too.
You would want to transform it into nldj: '{...}'\n'{...}'\n'{...}'\nso BigQuery could load it into tables.
Or imagine you are working with standard Firehose output where data has been written like a string of JSON objects {...}{...}{...}. No commas. You would want to prepare data for BigQuery (transform into nldj) from OBJECT_STRING to SRC variant format, i.e. {...}{...}{...} >>> '{...}'\n'{...}'\n'{...}'\n. See apostropees in there? That would define it as of type STRING and you would need to create a table with just one column: name: "src", type: "STRING".
This might be challenging task but I wrote a few handy helper functions. You will find them later.
So simply adding file format specifications in your
configwould define the processing logic and load all files into bigQuery correctly.
For example, you might want to define your tables in yaml config like so:
The first pipe called paypal_transaction has an array of individual JSON objects (deeply nested) and you would probably want to insert each individual nested object as one JSON record so you could parse it later with JSON_PARSE function in your data warehouse.
The second pipe GeoIP2-Country-Blocks-IPv4 needs to be parsed from CSV and be inserted into BigQuery table with the relevant schema having six columns. Here you would want to explicitly declare a CSV delimiter to help BigQuery load that data.
The third one which represents some poorly configured Kinesis stream output needs to be inserted as JSON but must be prepared for BigQuery first (transformed into NLDJ format).
The fourth one also needs to be loaded as NLDJ but it was compressed so you would want to uncompress it first.
How to load compressed files into BigQuery
If your file was compressed then you would want to decompress it first using zlib library. You would want to add a function loadGzJsonFileFromS3(). So here in this example we unzip the file first and then we pipe that stream into JSONparse which would extract JSON we need and pipe into createWriteStream into BigQuery.
Doing this you can load large files very effectively.
There are more examples in this Github repository with code including branching of these loading functions. For example, a function called checkSourceFileFormatAndIngest() defines the logic how to transform data formats and then loads data into BigQuery.
There are more examples in this Github repository with code including branching of these loading functions. For example, a function called checkSourceFileFormatAndIngest() defines the logic how to transform data formats and then loads data into BigQuery.
I am also using custom BigQuery jobIds in that example above. This is another way to prevent duplicates in BigQuery. In this case you don't need DynamoDB but I still use and insert extra metrics, i.e. number of rows inserted and a table name to generate statistics.
How to deploy with AWS Cloudformation
I don't want to create all those resources with AWS console. AWS Cloudformation is an easy way to automate deployment and provision all the resources with one click.
Amongst other benefits you will find it really easy to create production and staging environments and tidy up (delete) all resources.
Check it in Github repository with code.
In ./stack/cf-config.yaml you will find AWS Cloudformation** template describing all resources you might need for this tutorial. Including, for example, AWS Lambda role:
To deploy the service in your AWS account go to ./stack and run these 2 commands in your command line:
That lambdas.bq-shakhomirov.aws is a S3 bucket for your service artifacts where your lambda code will be saved. Replace it with yours.
How to load all files into BigQuery tables at once
This multi file upload feature might be useful when you need to load / reload all the files from the data lake into your data warehouse within a selected time frame , i.e. particular date, in one go.
The service must be able to scan your data lake if need and pick the files that match the description and time you need.
Let's imagine your data lake has files from different sources saved in AWS S3 having key prefix which contains BigQuery table name and date partitions, i.e.
So here you would want your service to scan the data lake bucket and select only files which are relevant for these three pipes: paypal_transaction, simple_transaction and some-other-transaction with date prefix 2021/10/04.
Then you would want ingest-manager to generate a final payload with all the file keys found and load them into BigQuery.
Final payload for ./test/data.json should have all files found in Data lake:
Having this
payloadin your local folder you can run$ npm run test(if your payload is in./test/data.json) in your command line and your micro service will load these files into Bigquery.
I added scripts to my ./package.json to run these commands.
For example, if in my command line I run $ npm run test-service the app in ./loadTestIngestManager.js will scan the data lake using pipe descriptions from test/integration/loadTestPipelines.json and produce an output with all files found. It will save it to test/integration/loadTestPayload.json.
Then if I run $ npm run test-load ./app.js ingest-manager would use that payload with files and send them to BigQuery.
Using these scripts you can easily write integration tests for files and formats you load into BigQuery.
You probably noticed that payload.json above is slightly different from the original S3 Obj created event payload:
That's only because in my environment I have another orchestrator service that is being triggered by S3 Obj created events that would create the payload for ingest-manager. That service can perform any other functions you need and it would just invoke ingest manager when needed.
Feel free to adjust the payload for ingest manager. You would want to add S3 key to event processing inside processEvent() function.
Conclusion
You've just learned how to create a Simple and reliable ingest manager for BigQuery written in Node.JS with some awesome features:
- Serverless design and AWS Lambda functions.
- It is very cost effective. Optimised for batch load jobs which means you don't need to pay for data loading. Basically it's free but check BigQuery load job limits.
- Can use streaming inserts (BigQuery streaming loading).
- Tailored for AWS but can be easily migrated to GCP, Azure.
- Infrastructure as code built with AWS Cloudformation. Deploy in one click in any other AWS account.
- Effective load job monitoring and file duplicates handling with AWS Dynamo.
- Custom BigQuery job ids. Another way to prevent duplication attempts if you don't want to use Dynamo.
- Support for unit and integration tests.
Many people would argue that Python would be the best choice for such task but I tend to disagree. All choices are good if they do the job. Previuosly I wrote How to achieve the same writing your code in Python and Python is one of my favourite programming languages. Most of my production pipelines were written in Python or Java.
My point is that you shouldn't limit yourself.
This tutorial is not about programming languages or their specific applications. I do think that there is certain cliche that data is for Python/Java only. It also upsets me a lot when I see data scientists who don’t use SQL (or don't know how to).
This project is about data engineering, modern data stacks, thinking outside the box, self learning, customisation, being language agnostic and being able to achieve the desired outcome with unconventional methods.



Mike
Mike is a Machine Learning Engineer / Python / Java Script Full stack dev / Middle shelf tequila connoisseur and accomplished napper. Stay tuned, read me on Medium https://medium.com/@mshakhomirov/membership and receive my unique content.
Comments
Jen Lopez November 13, 2021
Very useful.