How to Export millions of rows in chunks, capture real-time data changes or extract data and save it to the Cloud or locally.
Building a MySQL data connector for your data warehouse
Imagine you are a Data engineer and you were tasked to sync data from one of your MySQL database instances and your data warehouse.
This is a very common scenario in which you need to connect of of the most popular data sources to your data warehouse solution, i.e. Snowflake, Redshift or BigQuery. I previously wrote about modern data stack and various ways of doing it here.
This article is a detailed summary on how to extract and save data from relational database (MySQL) without using 3rd paty apps.
I will give you with a detailed explanation of Node.js serverless application built with AWS Lambda function. This microservice will extract data from MySQL database and can be ran locally on your machine or/and from AWS account on a schedule.
There is also a more advanced example of the same application which creates Node.JS streams to extract and save data from MySQL to your AWS S3 datalake.
Outline
You will learn how to:
- create a simple Node.js app with AWS Lambda.
- use Node.js streams to optimise memory consumption.
- extract data and save it locally in CSV and JSON formats.
- export it into the Cloud Storage.
- use
yamlconfig for your queries. - deploy and schedule it.
$ npm run testcommand would export a hundred million rows in chunks to Cloud Storage.
This tutorial might be useful for data engineers and everyone who works with MySQL databases or wants to learn how to connect various arbitrary data sources to data warehouse solutions.
Prerequisites, Libraries and setup
TOOLS
- Node.js and Node package manager installed
- Basic understanding of cloud computing (Amazon Web Services account), AWS CLI and AWS SDK
- Google Cloud Platform or AWS account depending on which Cloud Storage you're using.
- Shell (Command line interface) commands and scripting (Advanced).
TECHNIQUES
- Good knowledge of Node.JS (intermediate). You will create a Lambda Function.
- You must understand Node.JS basic concepts, i.e. async funcitons, Node packages and how the code works.
- basic debugging (consoles, print statements)
- loops: i.e. for
- branches: if, if/else, switches
- Shell commands and scripting as you would want to deploy your Lambda using AWS CLI from command line and be able to test it locally.
How to export data in chunks using MySQL native features
You would want to use SELECT * INTO 'file.csv' to achieve this:
https://gist.github.com/mshakhomirov/f54c634d9923c4fa0a36fca655277f9a
With a bit of tweaking and changing the outfile you'll achieve the desired outcome.
However, this is a manual operation and keep in mind that you would want to limit your range in where clause using indexed column. Otherwise your database will be having hard times.
Very basic MySQL data connector with Node.JS
Skip this part if you are after more advanced examples with node.js streaming, data transformation and S3 upload.
- Create a new folder for your Lamda micro service:
$ mkdir mysql-connector.$ cd mysql-connector.$ npm init. - Use
npmto install mysql package for your lambda:$npm i mysql2@2.0.0 - Install run-local-lambda package. We will use it to trigger and test Lambda locally:
$ npm i run-local-lambda@1.1.1 - In your Lambda root directory create a
configfile to define the pipeline configuration and tables to use:
https://gist.github.com/mshakhomirov/7c2065799179bb1f6f58549106188f87
- Create an
asyncfunction in your main application file./app.jsto run SQL query from./config.jsonfile.
Your application folder now should look like this: https://gist.github.com/mshakhomirov/1aca62a66767b01679c0bef2329b5d1c
Your main application file ./app.js would look like this:
https://gist.github.com/mshakhomirov/31dba2bf1b260cf13e8d22afb21d21e9
This is the gist of how to export data from MySQL programmatically. Very simple.
Run $ npm run test in your command line and that would export data from MySQL database. Make sure your credentials and database host address are correct.
Now you can change query in your ./config.json file and run them programmatically.
How to use Node.js stream and export data from MySQL
First of all, why use Node.js stream?
Well if your dataset is more than your memory then you would want to extract data in chunks like we did in step 1. that what stream is for.
It can help you to optimise your app's memory and export data without loading all of the rows into memory.
If you use AWS Lambda or GCP Cloud functions it helps to save money and not to overprovision the memory resource.
Very often 128 Mb of allocated memory is enough to export a few millions rows.
So with Node.js
streamyou can connect MySQL to your data warehouse more efficiently.
The gist of it
Let's say you want to extract data from MySQL row by row and save it locally as CSV. The example below would work with npm packages mysql2 and csv-stringify.
https://gist.github.com/mshakhomirov/d300ef636910235669150a10deefb6bf
How to export data from MySQL efficiently with stream and save locally as CSV
All you need is a queryDbAndSave() function. Try to add this async example below into your processEvent() function.
https://gist.github.com/mshakhomirov/491c4eb380e26496103d8bbb236e208c
Add this to your processEvent() function like so:
https://gist.github.com/mshakhomirov/b689f77578ed527b4dd0dfca6008fc36
Next in your command line run: $ npm run test.
Got the idea? Cool. Let's continue to more examples.
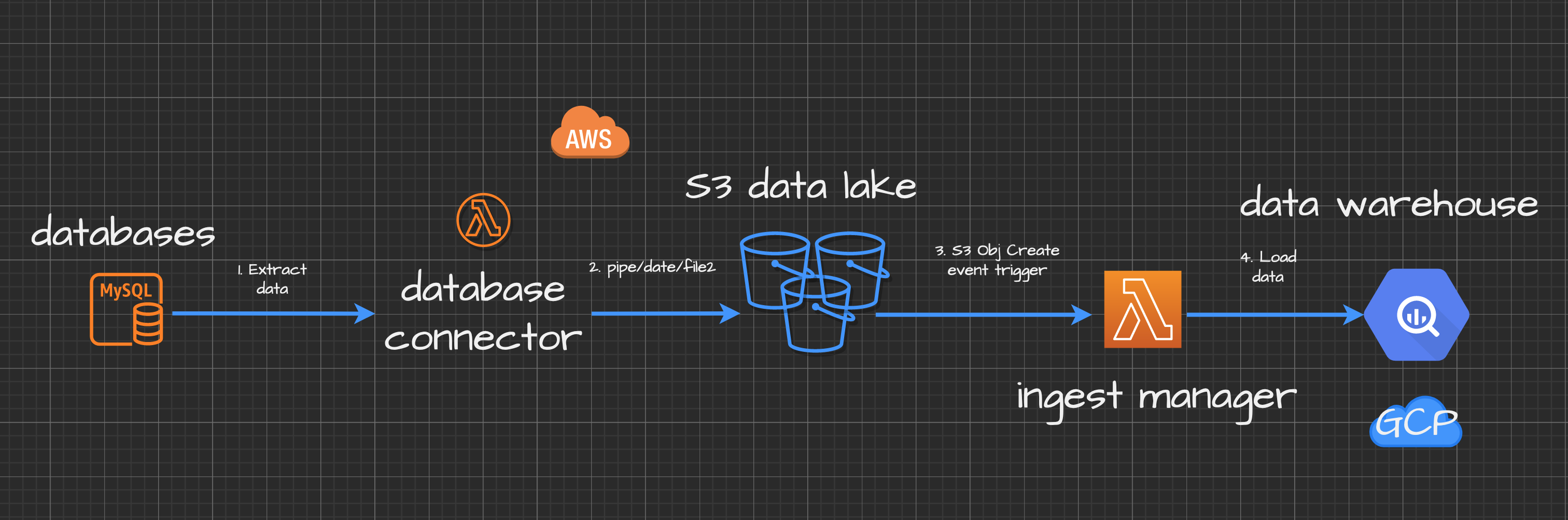
How to export data from MySQL and pipe save that stream to GCP's Cloud Storage or AWS S3
This example will save your SQL query results to AWS S3 or GCP Cloud Storage and no need to over provision memory resources.
In my scenario I would want to stream query results to my S3 datalake bucket and transform JSON into ndJSON. In this way I could easily trigger further data ingestion with soome other service when file has been created in Cloud Storage.
If you want to learn how to do it check my tutroial on how to handle data loading into your data warehouse.
https://towardsdatascience.com/how-to-handle-data-loading-in-bigquery-with-serverless-ingest-manager-and-node-js-4f99fba92436
To stream-save query results you would want to add a new branch to your queryDbAndSave() function:
https://gist.github.com/mshakhomirov/5b935158985446b9b9bbd56edeff29eb
This example will work for the same modules but you would want to include these ones too:
npm i aws-sdk@2.1001.0the that's used in AWS Lambda environments at the moment of writing this article. Theck current evironments here so you could then simple exclude it from deployment artifacts.through2@4.0.2"a wrapper library making easier to constructstreams.
So now if add another MySQL pipe to your ./config.json:
https://gist.github.com/mshakhomirov/c537a5c86dba71cd4d89033fd1d62506
Run
$ npm run testin your command line and it will export the data from MySQL and save it as one file instreammode to your Cloud Storage.
How export data as a stream and save it in chunks to Cloud Storage
You also might want to save data locally or to AWS S3 in chunks, i.e. in batch mode. The snippet below explains how to do it.
You would want to declare an output file batch size in rows at the top of your ./app.js: const BATCH_SIZE = process.env.BATCH_SIZE || 3000;
Then you would want to evaluate SQL query size. You could use another async function for that:
https://gist.github.com/mshakhomirov/ece0d6afc0d805f01bafc7335a5e1abc
Add another branch to your queryDbAndSave() function and export data in chunks each time checking if it's a time to finish:
https://gist.github.com/mshakhomirov/18eef36fd2c5d0e1ffacab28824877c3
Final solution for processEvent() function in ./app.js:
Don't forget to run $npm i moment. ./app.js will use to construct file keys to save objects.
https://gist.github.com/mshakhomirov/fc2ad8b2b0904e942cc8c745f131485b
How to use yaml config
The final solution which can be found in this repository use npm config and yaml definitions for your MySQL pipes.
I prefer using
yamlsimply because it is easier to read when you add those long SQL queries.
Sample ./config/staging.yaml would usually look:
https://gist.github.com/mshakhomirov/5866cfe527113a14982406f583e4308d
It is also more intuitive in my opinion when you need to separate live and staging environments. In your command line run $ npm i config. So your final application folder with ./config/ instead ./config.json would look like:
https://gist.github.com/mshakhomirov/ecfa4f896ede8fbc52b4c25034e668b8
How to deploy the solution
There are three ways to do it.
- Beginners would probably choose to use web UI either deploy the solution as AWS Lambda or GCP Cloud function
- More advanced users would probably want to create a deployment shell script
./deploy.shlike this one below. Run$ ./deploy.shin your command line and it will deploy the Lambda: https://gist.github.com/mshakhomirov/43df39dbdfda83dfe2c47eb5a8369cea - Deploy with Infrastructure as code using either Tarraform or AWS Cloudformation. Handy AWS Cloudformation template can be found in this project's repository on github.
During the deployment make sure you configured all access roles and Security groups properly. For example, when your MySQL database is in AWS then your Lambda function must be deployed in the same VPC to be able to access it. Once you enable VPC support in Lambda your function no longer has access to anything outside your VPC, which includes S3. With S3 specifically you can use [VPC Endpoints][15] to resolve this.
Conclusion
This is a simple and reliable data export solution which allows you to extract data from MySQL database programmatically with low memory usage. This way you can create a simple and reliable MySQL data connector with some awesome features:
- Extract MySQL data programmatically by just running
$npm run testfrom your command line. - Use
yamldefinitions to describe your MySQL pipes. - Perform
dryRunto evaluate SQL size. - Export data with
Node.js streamsto avoid memory over provisioning. - Save data exports on your local device.
- Save data to the Cloud as one file or in chunks.
- One click deployment and scheduling with Infrastructure as code Check Github repository for more information.
Some real-time integrations might be expensive and often it depnds on the size of the data you have. Just imagine each row inserted into MySQL would trigger the Lambda to export and insert it into your data warehouse. There is a better way to monitor and control data ingestion like that.
Just a few days ago I used it to export 56 million of rows from MySQL. Then I saved them in chunks to my data lake in AWS S3. For example, I have data loading manager and every time file lands in data lake it sends data to my BigQuery data warehouse. I wrote about it in this post before: https://towardsdatascience.com/how-to-handle-data-loading-in-bigquery-with-serverless-ingest-manager-and-node-js-4f99fba92436
So exporting my MySQL data and loading it into my data warehouse was quick and easy.
Resources
- [1] https://towardsdatascience.com/how-to-handle-data-loading-in-bigquery-with-serverless-ingest-manager-and-node-js-4f99fba92436
- [2] https://dev.mysql.com/doc/refman/5.7/en/select-into.html
- [3] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Integrating.SaveIntoS3.html
- [4] https://www.npmjs.com/package/mysql2
- [5] https://nodejs.org/api/stream.html
- [6] http://ndjson.org/
- [7] https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.html
- [8] https://aws.amazon.com/blogs/database/capturing-data-changes-in-amazon-aurora-using-aws-lambda/
- [9] https://stackoverflow.com/questions/12333260/export-a-mysql-table-with-hundreds-of-millions-of-records-in-chunks
- [10] https://stackoverflow.com/questions/1119312/mysql-export-into-outfile-csv-escaping-chars/1197023
- [11] https://joshuaotwell.com/select-into-outfile-examples-in-mysql/
- [12] https://github.com/sidorares/node-mysql2/issues/677
- [13] https://aws.amazon.com/blogs/database/best-practices-for-exporting-and-importing-data-from-amazon-aurora-mysql-to-amazon-s3/
- [14] https://blog.risingstack.com/node-js-mysql-example-handling-hundred-gigabytes-of-data/



Mike
Mike is a Machine Learning Engineer / Python / Java Script Full stack dev / Middle shelf tequila connoisseur and accomplished napper. Stay tuned, read me on Medium https://medium.com/@mshakhomirov/membership and receive my unique content.
Comments
Jen Lopez November 13, 2021
Very useful.