Loading data into BigQuery using schemas in 20 minutes.
Welcome to part II of the tutorial series "Build a Data warehouse in the Cloud using BigQuery". In this installment, we'll be building a Cloud Function to load data from Google Storage into BigQuery.
Our Cloud function is built on top of the hybrid solution that we completed in Part I
After Part 1 we have all our source files in Google Storage. Using the techniques that we'll cover for this part, you will have a foundation to build any sort of table in BigQuery Data Warehouse.
We will also be going over the details of wiring up a simple data loading system, along with covering some guidelines for schemas, different file formats and BigQuery Python API components, e.g. load_table_from_json, load_table_from_file and load_table_from_dataframe.
Before trying this article, follow the Python setup instructions in the BigQuery Quickstart Using Client Libraries .
Project layout:
Part 1: Sync only new/changed files from AWS S3 to GCP cloud storage.
You are here >>> Part 2: Loading data into BigQuery. Create tables using schemas. We'll use yaml to create config file.
Part 3: Create streaming ETL pipeline with load monitoring and error handling.
Prerequisites:
- Google developer account.
- Google Command Line Interface. Follow this article to install it: https://cloud.google.com/sdk/ .
-
Finally, we'll need Python to run our core application.
Just install Anaconda distribution .
Before starting, let's think about the data we are going to load into BigQuery.
-
BigQuery has a specific limitation regarding the data format: JSON data must be newline delimited . Each JSON object must be on a separate line in the file:
{"id": "1", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
{"id": "2", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
However, we also want to load data from JSON:
[
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]},
{"id":"2","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
]
We want to load data from file when it's not a newline delimited. Everything is on one line, no line breaks:
{"id": "1", "first_name": "John"}{"id": "12", "first_name": "Peter"}{"id": "3", "first_name": "Cornelia"}
We want to load data from JSON as CSV where each line is a record (Snowflake like)
We want to load data from CSV with column delimiters
These are the most popular source formats I met. If you want to know more about other formats like parquet, Avro and ORC please check the official Google documentation
Let's do it.
How do we do it
We will be using BigQuery Python API in order to process and load files. You can find usage guides here - https://cloud.google.com/bigquery/docs/quickstarts/quickstart-client-libraries.
We will also need to have a Google service account in order to use Google account credentials. We have already done that in Part 1 but just in case you are only interested in this particular tutorial this page contains the official instructions for Google managed accounts: How to create service account. After this you will be able to download your credentials and use Google API programmatically with Node.js. Your credentials file will look like this (example):
./your-google-project-12345.json
{
"type": "service_account",
"project_id": "your-project",
"private_key_id": "1202355D6DFGHJK54A223423DAD34320F5435D",
"private_key": "-----BEGIN PRIVATE KEY-----\ASDFGHJKLWQERTYUILKJHGFOIUYTREQWEQWE4BJDM61T4S0WW3XKXHIGRV\NRTPRDALWER3/H94KHCKCD3TEJBRWER4CX9RYCIT1BY7RDBBVBCTWERTYFGHCVBNMLKXCVBNM,MRaSIo=\n-----END PRIVATE KEY-----\n",
"client_email": "your-project-adminsdk@your-project.iam.gserviceaccount.com",
"client_id": "1234567890",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/your-project-adminsdk%40your-project.iam.gserviceaccount.com"
}
Clone Starter Repository
Run the following commands to clone the starter project and install the dependencies
git clone https://github.com/mshakhomirov/bigquery-etl-tutorial.git
cd bigquery-etl-tutorial
git checkout part2
The master branch includes a base directory template for Part 1, with dependencies declared in package.json.
After you did git checkout part2 you will be in branch for this part with all the Python code we need.
Basic Data Load using CLI
First, let's create just one dataset staging and one table called table_1 as an example.
Use your Google account credentials (replace the file name to match yours) and in command line run this:
export GOOGLE_APPLICATION_CREDENTIALS="./client-50b5355d654a.json"
Then in your command line run these two commands which will create the dataset and a table:
bq mk staging
bq mk staging.table_1 ./schemas/schema.json
Notice that we used ./schemas/schema.json to define the table. Have a look at this file:
[
{
"name": "id",
"type": "INT64",
"mode": "NULLABLE"
},
{
"name": "first_name",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "last_name",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "dob",
"type": "DATE",
"mode": "NULLABLE"
},
{
"name": "addresses",
"type": "RECORD",
"mode": "REPEATED",
"fields": [
{
"name": "status",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "address",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "city",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "state",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "zip",
"type": "INT64",
"mode": "NULLABLE"
},
{
"name": "numberOfYears",
"type": "INT64",
"mode": "NULLABLE"
}
]
}
]
After you run this command in your command line you will see Table 'your-project:staging.table_1' successfully created. and if you go to Google web console new table will be there.
Now let's load some data in. Use the file ./test_files/data_new_line_delimited_json.json and run this in your command line:
bq load --source_format=NEWLINE_DELIMITED_JSON \
staging.table_1 test_files/data_new_line_delimited_json.json
Run this to select the data from your table:
$ bq query 'select first_name, last_name, dob from staging.table_1' Waiting on bqjob_r2c64623d43d6b68d_0000016de49a1248_1 ... (0s) Current status: DONE +------------+-----------+------------+ | first_name | last_name | dob | +------------+-----------+------------+ | John | Doe | 1968-01-22 | | Peter | Doe | 1968-01-22 | +------------+-----------+------------+Great! The data is there.
Getting Started With Cloud function.
How do we do it:
-
We want our Cloud Function to use ./schemas.yaml config file where we keep our table names, their schemas and data formats.
-
Once we deployed our Cloud Function we don't want to touch it anymore if we need to create a new table and/or set up a new data pipeline. That should be done with just one file schemas.yaml by adding a new record set.
-
Cloud Function will be triggered by new bucket create/update event, e.g. new file saved.
-
Cloud Function will read the file, check it's name and if it is in our schemas.yaml table names list, it will insert the data into the relevant BigQuery table.
-
If table doesn't exist in BigQuery yet then Cloud Function will create it.
Let's create a bucket called staging_files and upload our test_files there. In your command line run this:
$ gcloud config set project your-project
$ gsutil mb -c regional -l europe-west2 gs://project_staging_files
$ gsutil cp ./test_files/* gs://project_staging_files/
The last command will copy all the files into your project_staging_files folder so if you go to console you will see it there:
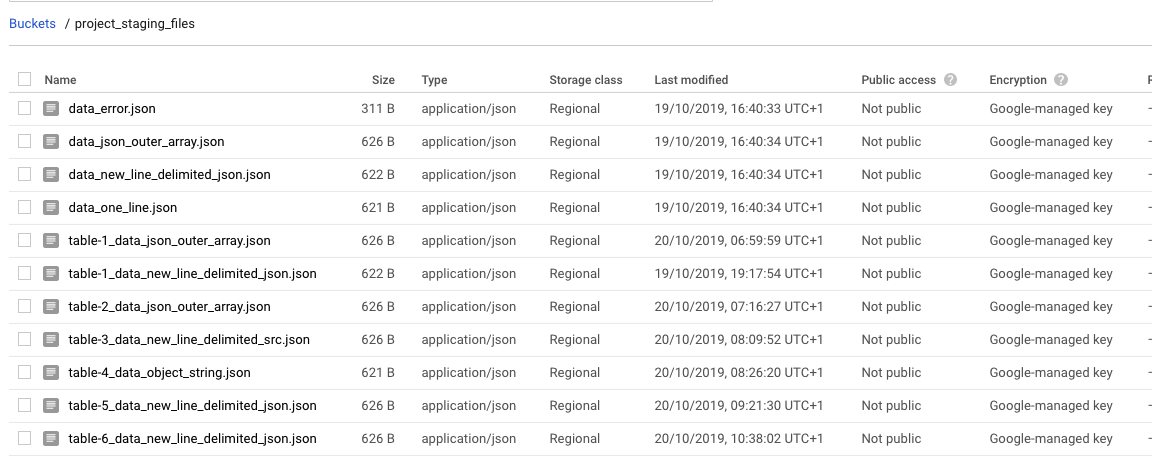
Let's create our Clooud function file called:
./main.py
'''
This simple a Cloud Function responsible for:
- Loading data using schemas
- Loading data from different data file formats
'''
import json
import logging
import os
import traceback
from datetime import datetime
import io
import re
from six import StringIO
from six import BytesIO
from google.api_core import retry
from google.cloud import bigquery
# from google.cloud import firestore
# from google.cloud import pubsub_v1
from google.cloud import storage
import pytz
import pandas
import yaml
with open("./schemas.yaml") as schema_file:
config = yaml.load(schema_file)
PROJECT_ID = os.getenv('GCP_PROJECT')
BQ_DATASET = 'staging'
CS = storage.Client()
BQ = bigquery.Client()
job_config = bigquery.LoadJobConfig()
"""
This is our Cloud Function:
"""
def streaming(data, context):
bucketname = data['bucket']
filename = data['name']
timeCreated = data['timeCreated']
try:
for table in config:
tableName = table.get('name')
# Check which table the file belongs to and load:
if re.search(tableName.replace('_', '-'), filename) or re.search(tableName, filename):
tableSchema = table.get('schema')
# check if table exists, otherwise create:
_check_if_table_exists(tableName,tableSchema)
# Check source file data format. Depending on that we'll use different methods:
tableFormat = table.get('format')
if tableFormat == 'NEWLINE_DELIMITED_JSON':
_load_table_from_uri(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'OUTER_ARRAY_JSON':
_load_table_from_json(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'SRC':
_load_table_as_src(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'OBJECT_STRING':
_load_table_from_object_string(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'DF':
_load_table_from_dataframe(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'DF_NORMALIZED':
_load_table_as_df_normalized(data['bucket'], data['name'], tableSchema, tableName)
except Exception:
_handle_error()
def _insert_rows_into_bigquery(bucket_name, file_name):
blob = CS.get_bucket(bucket_name).blob(file_name)
row = json.loads(blob.download_as_string())
print('row: ', row)
table = BQ.dataset(BQ_DATASET).table(BQ_TABLE)
errors = BQ.insert_rows_json(table,
json_rows=[row],
row_ids=[file_name],
retry=retry.Retry(deadline=30))
print(errors)
if errors != []:
raise BigQueryError(errors)
def _load_table_from_json(bucket_name, file_name, tableSchema, tableName):
blob = CS.get_bucket(bucket_name).blob(file_name)
#! source data file format must be outer array JSON:
"""
[
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]},
{"id":"2","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
]
"""
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND'
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
load_job = BQ.load_table_from_json(
body,
table_id,
job_config=job_config,
)
load_job.result() # Waits for table load to complete.
print("Job finished.")
def _load_table_as_src(bucket_name, file_name, tableSchema, tableName):
# ! source file must be outer array JSON
# ! this will work for CSV where a row is A JSON string --> SRC column (Snowflake like)
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.CSV,
# something that doesn't exist in your data file:
job_config.field_delimiter =";"
# Notice that ';' worked because the snippet data does not contain ';'
job_config.write_disposition = 'WRITE_APPEND',
data_str = u"\n".join(json.dumps(item) for item in body)
print('data_str :', data_str)
data_file = io.BytesIO(data_str.encode())
print('data_file :', data_file)
load_job = BQ.load_table_from_file(
data_file,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _load_table_from_object_string(bucket_name, file_name, tableSchema, tableName):
# ! source file must be object string, e.g.:
"""
{"id": "1", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}{"id": "2", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
"""
# ! we will convert body to a new line delimited JSON
blob = CS.get_bucket(bucket_name).blob(file_name)
blob = blob.download_as_string().decode()
# Transform object string data into JSON outer array string:
blob = json.dumps('[' + blob.replace('}{', '},{') + ']')
# Load as JSON:
body = json.loads(blob)
# Create an array of string elements from JSON:
jsonReady = [json.dumps(record) for record in json.loads(body)]
# Now join them to create new line delimited JSON:
data_str = u"\n".join(jsonReady)
print('data_file :', data_str)
# Create file to load into BigQuery:
data_file = StringIO(data_str)
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND',
load_job = BQ.load_table_from_file(
data_file,
table_id,
job_config=job_config,
)
load_job.result() # Waits for table load to complete.
print("Job finished.")
def _check_if_table_exists(tableName,tableSchema):
# get table_id reference
table_id = BQ.dataset(BQ_DATASET).table(tableName)
# check if table exists, otherwise create
try:
BQ.get_table(table_id)
except Exception:
logging.warn('Creating table: %s' % (tableName))
schema = create_schema_from_yaml(tableSchema)
table = bigquery.Table(table_id, schema=schema)
table = BQ.create_table(table)
print("Created table {}.{}.{}".format(table.project, table.dataset_id, table.table_id))
# BQ.create_dataset(dataset_ref)
def _load_table_from_uri(bucket_name, file_name, tableSchema, tableName):
# ! source file must be like this:
"""
{"id": "1", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
{"id": "2", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
"""
# ! source file must be the same.
#! if source file is not a NEWLINE_DELIMITED_JSON then you need to load it with blob, convert to JSON and then load as file.
uri = 'gs://%s/%s' % (bucket_name, file_name)
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
print(schema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND',
load_job = BQ.load_table_from_uri(
uri,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _load_table_from_dataframe(bucket_name, file_name, tableSchema, tableName):
"""
Source data file must be outer JSON
"""
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
df = pandas.DataFrame(
body,
# In the loaded table, the column order reflects the order of the
# columns in the DataFrame.
columns=["id", "first_name","last_name","dob","addresses"],
)
df['addresses'] = df.addresses.astype(str)
df = df[['id','first_name','last_name','dob','addresses']]
load_job = BQ.load_table_from_dataframe(
df,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _load_table_as_df_normalized(bucket_name, file_name, tableSchema, tableName):
"""
Source data file must be outer JSON
"""
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
df = pandas.io.json.json_normalize(data=body, record_path='addresses',
meta=[ 'id' ,'first_name', 'last_name', 'dob']
, record_prefix='addresses_'
,errors='ignore')
df = df[['id','first_name','last_name','dob','addresses_status','addresses_address','addresses_city','addresses_state','addresses_zip','addresses_numberOfYears']]
load_job = BQ.load_table_from_dataframe(
df,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _handle_error():
message = 'Error streaming file. Cause: %s' % (traceback.format_exc())
print(message)
def create_schema_from_yaml(table_schema):
schema = []
for column in table_schema:
schemaField = bigquery.SchemaField(column['name'], column['type'], column['mode'])
schema.append(schemaField)
if column['type'] == 'RECORD':
schemaField._fields = create_schema_from_yaml(column['fields'])
return schema
class BigQueryError(Exception):
'''Exception raised whenever a BigQuery error happened'''
def __init__(self, errors):
super().__init__(self._format(errors))
self.errors = errors
def _format(self, errors):
err = []
for error in errors:
err.extend(error['errors'])
return json.dumps(err)
Looks massive but there is nothing super difficult about it.
It contains 6 different functions to process the data we have in our source files we copied a moment before. Each of them handles one of the most popular scenarios to handle the data in modern datalakes. We described source data files types in the beginning of this article but essentially they are different types of JSON and CSV. Have a look at ./test_files folder. Each file with table_ prefix represents a use case and has it's own data structure. Also take your time to familiarise yourself with the code or just keep reading and I will talk you through each step.
Now let's create ./schemas.yaml.
yaml format is much easier to read than JSON.
- name: table_1
size: large
format: NEWLINE_DELIMITED_JSON
columns: []
schema:
- name: "id"
type: "INT64"
mode: "NULLABLE"
- name: "first_name"
type: "STRING"
mode: "NULLABLE"
- name: "last_name"
type: "STRING"
mode: "NULLABLE"
- name: "dob"
type: "DATE"
mode: "NULLABLE"
- name: "addresses"
type: "RECORD"
mode: "REPEATED"
fields:
- name: "status"
type: "STRING"
mode: "NULLABLE"
- name: "address"
type: "STRING"
mode: "NULLABLE"
- name: "city"
type: "STRING"
mode: "NULLABLE"
- name: "state"
type: "STRING"
mode: "NULLABLE"
- name: "zip"
type: "INT64"
mode: "NULLABLE"
- name: "numberOfYears"
type: "INT64"
mode: "NULLABLE"
- name: table_2
size: large
format: OUTER_ARRAY_JSON
columns: []
schema:
- name: "id"
type: "INT64"
mode: "NULLABLE"
- name: "first_name"
type: "STRING"
mode: "NULLABLE"
- name: "last_name"
type: "STRING"
mode: "NULLABLE"
- name: "dob"
type: "DATE"
mode: "NULLABLE"
- name: "addresses"
type: "RECORD"
mode: "REPEATED"
fields:
- name: "status"
type: "STRING"
mode: "NULLABLE"
- name: "address"
type: "STRING"
mode: "NULLABLE"
- name: "city"
type: "STRING"
mode: "NULLABLE"
- name: "state"
type: "STRING"
mode: "NULLABLE"
- name: "zip"
type: "INT64"
mode: "NULLABLE"
- name: "numberOfYears"
type: "INT64"
mode: "NULLABLE"
- name: table_3
size: large
format: SRC
columns: []
schema:
- name: "src"
type: "STRING"
mode: "NULLABLE"
- name: table_4
size: large
format: OBJECT_STRING
columns: []
schema:
- name: "id"
type: "INT64"
mode: "NULLABLE"
- name: "first_name"
type: "STRING"
mode: "NULLABLE"
- name: "last_name"
type: "STRING"
mode: "NULLABLE"
- name: "dob"
type: "DATE"
mode: "NULLABLE"
- name: "addresses"
type: "RECORD"
mode: "REPEATED"
fields:
- name: "status"
type: "STRING"
mode: "NULLABLE"
- name: "address"
type: "STRING"
mode: "NULLABLE"
- name: "city"
type: "STRING"
mode: "NULLABLE"
- name: "state"
type: "STRING"
mode: "NULLABLE"
- name: "zip"
type: "INT64"
mode: "NULLABLE"
- name: "numberOfYears"
type: "INT64"
mode: "NULLABLE"
- name: table_5
size: large
format: DF
columns: []
schema:
- name: "id"
type: "STRING"
mode: "NULLABLE"
- name: "first_name"
type: "STRING"
mode: "NULLABLE"
- name: "last_name"
type: "STRING"
mode: "NULLABLE"
- name: "dob"
type: "STRING"
mode: "NULLABLE"
- name: "addresses"
type: "STRING"
mode: "NULLABLE"
- name: table_6
size: large
format: DF_NORMALIZED
columns: []
schema:
- name: "id"
type: "STRING"
mode: "NULLABLE"
- name: "first_name"
type: "STRING"
mode: "NULLABLE"
- name: "last_name"
type: "STRING"
mode: "NULLABLE"
- name: "dob"
type: "STRING"
mode: "NULLABLE"
- name: "addresses_status"
type: "STRING"
mode: "NULLABLE"
- name: "addresses_address"
type: "STRING"
mode: "NULLABLE"
- name: "addresses_city"
type: "STRING"
mode: "NULLABLE"
- name: "addresses_state"
type: "STRING"
mode: "NULLABLE"
- name: "addresses_zip"
type: "STRING"
mode: "NULLABLE"
- name: "addresses_numberOfYears"
type: "STRING"
mode: "NULLABLE"
You can see table names and their schemas there. Remember we created table_1 with command line using schema.json file? Well, that's how it looks in yaml. For example, name: table_4 is a table name and also a file name prefixe, e.g. gs://project_staging_files/table-4_data_object_string.json
Test your Cloud Function locally
Now let's see how files with different data structure can be loaded into BigQuery using schemas and BigQuery Python API .
Just a few words about why we are using schemas. Of course, BigQuery has autodetect feature which works just fine. However, I prefer to take everything under control and define field types myself. This might be very useful when you start getting load errors. You know your schema so it's easier to understand what happend with data so the load went wrong.
You might notice that we're using test.py file in our project.
./test.js:
from event import data
print(data['bucket'])
print(data['name'])
print(data['timeCreated'])
from main import streaming
streaming(data, 'context')
You can see that we declared from event import data. File ./event.py is to simulate Create object event. This file should have these contents:
./event.py:
data = {"name": "table-1_data_new_line_delimited_json.json", \
"bucket":"project_staging_files", \
"timeCreated": "2019-09-24 15:54:54"\
}\
All we really care about is the name of the bucket and object key here. So change it to reflect your Google Storage test files accordingly.
Now run python test in your command line. It will trigger your local Cloud Function which will use the file in Google Storage you specified in event data['name]:
$ python test
Job finished.
Now if you run SELECT you will see two new records in table_1:
$ bq query 'select first_name, last_name, dob from staging.table_1'
Waiting on bqjob_r5f1305f93091f0a5_0000016de8e9171c_1 ... (0s) Current status: DONE
+------------+-----------+------------+
| first_name | last_name | dob |
+------------+-----------+------------+
| John | Doe | 1968-01-22 |
| Peter | Doe | 1968-01-22 |
| John | Doe | 1968-01-22 |
| Peter | Doe | 1968-01-22 |
+------------+-----------+------------+
When your source data file is JSON with outer array brackets.
Now let's try table_2 which is exactly the same as table_1 but the source data file is an JSON with outer array brackets:
[
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]},
{"id":"2","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
]
Remember we talked about JSON format limitation? JSON files must be New line delimited
To deal with this situation we created a fucntion called _load_table_from_json:
def _load_table_from_json(bucket_name, file_name, tableSchema, tableName):
blob = CS.get_bucket(bucket_name).blob(file_name)
#! source data file format must be outer array JSON:
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND'
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
load_job = BQ.load_table_from_json(
body,
table_id,
job_config=job_config,
)
load_job.result() # Waits for table load to complete.
print("Job finished.")
It converts our JSON file to a NEWLINE_DELIMITED_JSON before the load.
Change your ./event.py to use file for table_2:
# data = {"name": "table-1_data_new_line_delimited_json.json", \
data = {"name": "table-2_data_json_outer_array.json", \
# data = {"name": "table-3_data_new_line_delimited_src.json", \
# data = {"name": "table-4_data_object_string.json", \
# data = {"name": "table-5_data_new_line_delimited_json.json", \
# data = {"name": "table-6_data_new_line_delimited_json.json", \
"bucket":"project_staging_files", \
"timeCreated": "2019-09-24 15:54:54"\
}\
In your command line run:
$ python test
Job finished.
And SELECT statement will show new rows added to table_2 even if it wasn't created beforehand. Our Cloud function took care of it. It used schema.yaml file to create a new table_2 which didn't exist.
When you need to load each JSON object (row) as one column (field)
Sometimes we need to load each JSON object we have in our source file as one row (like in SRC format in Snowflake ) and JSON parse function later. Very standard task for ETL. Very useful when we don't want to worry about schema changes.
To deal with this situation I created a function called _load_table_as_src:
def _load_table_as_src(bucket_name, file_name, tableSchema, tableName):
# ! source file must be outer array JSON
# ! this will work for CSV where a row is A JSON string --> SRC column (Snowflake like)
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.CSV,
# something that doesn't exist in your data file:
job_config.field_delimiter =";"
# Notice that ';' worked because the snippet data does not contain ';'
job_config.write_disposition = 'WRITE_APPEND',
data_str = u"\n".join(json.dumps(item) for item in body)
print('data_str :', data_str)
data_file = io.BytesIO(data_str.encode())
print('data_file :', data_file)
load_job = BQ.load_table_from_file(
data_file,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
It loads each JSON object as CSV string column so then you can parse it in BigQuery.
Change the ./event.py to use data = {"name": "table-3_data_new_line_delimited_src.json", \ As a result you will have this:

Load data into BigQuery from JSON object string (when it doesn't have outer array brackets and commas)
Sometime you have data in object string without commas separating your records (objects):
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}{"id":"2","first_name":"Peter","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
This case is a bit tricky but it can be handled too. I created a _load_table_from_object_string function.
It transforms your source file to outer array JSON first and then loads it. BigQuery Python API load_table_from_file is very useful for cases like this.
def _load_table_from_object_string(bucket_name, file_name, tableSchema, tableName):
# ! we will convert body to a new line delimited JSON
blob = CS.get_bucket(bucket_name).blob(file_name)
blob = blob.download_as_string().decode()
# Transform object string data into JSON outer array string:
blob = json.dumps('[' + blob.replace('}{', '},{') + ']')
# Load as JSON:
body = json.loads(blob)
# Create an array of string elements from JSON:
jsonReady = [json.dumps(record) for record in json.loads(body)]
# Now join them to create new line delimited JSON:
data_str = u"\n".join(jsonReady)
print('data_file :', data_str)
# Create file to load into BigQuery:
data_file = StringIO(data_str)
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND',
load_job = BQ.load_table_from_file(
data_file,
table_id,
job_config=job_config,
)
load_job.result() # Waits for table load to complete.
print("Job finished.")
Try it by changing the ./event.py to use file data = {"name": "table-4_data_object_string.json", \
Again don't worry about table schema definition. We have it in schemas.yaml table_4. Cloud Function will create it for you.
Load data from outer array JSON with Pandas dataframe
Yup. Sometimes you need to swap columns and/or use Pandas to transform data.
Function _load_table_from_dataframe takes care of this:
def _load_table_from_dataframe(bucket_name, file_name, tableSchema, tableName):
"""
Source data file must be outer JSON
"""
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
df = pandas.DataFrame(
body,
# In the loaded table, the column order reflects the order of the
# columns in the DataFrame.
columns=["id", "first_name","last_name","dob","addresses"],
)
df['addresses'] = df.addresses.astype(str)
df = df[['id','first_name','last_name','dob','addresses']]
load_job = BQ.load_table_from_dataframe(
df,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
Have a look table_5 in ./schemas.yaml:
- name: table_5
size: large
format: DF
columns: []
schema:
- name: "id"
type: "STRING"
mode: "NULLABLE"
- name: "first_name"
type: "STRING"
mode: "NULLABLE"
- name: "last_name"
type: "STRING"
mode: "NULLABLE"
- name: "dob"
type: "STRING"
mode: "NULLABLE"
- name: "addresses"
type: "STRING"
mode: "NULLABLE"
As a result you will have this in your table_5:

You can JSON parse addresses now.
INSERT data from deeply nested JSON when you need to normalise data.
Sometimes you have data with nested JSON like in our case.
Often we would like to have it in standard columnar format. To handle this case I created _load_table_as_df_normalized function.
def _load_table_as_df_normalized(bucket_name, file_name, tableSchema, tableName):
"""
Source data file must be outer JSON
"""
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
df = pandas.io.json.json_normalize(data=body, record_path='addresses',
meta=[ 'id' ,'first_name', 'last_name', 'dob']
, record_prefix='addresses_'
,errors='ignore')
df = df[['id','first_name','last_name','dob','addresses_status','addresses_address','addresses_city','addresses_state','addresses_zip','addresses_numberOfYears']]
load_job = BQ.load_table_from_dataframe(
df,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
Change your ./event.py to use data = {"name": "table-6_data_new_line_delimited_json.json", \
As a result you will have this in your table_6:

How to create BigQuery schema object from yaml
I wrote a function called create_schema_from_yaml to help with this:
def create_schema_from_yaml(table_schema):
schema = []
for column in table_schema:
schemaField = bigquery.SchemaField(column['name'], column['type'], column['mode'])
schema.append(schemaField)
if column['type'] == 'RECORD':
schemaField._fields = create_schema_from_yaml(column['fields'])
return schema
It will transform our yaml definition into an object like so:
[
SchemaField('id', 'INT64', 'NULLABLE', None, ()),
SchemaField('first_name', 'STRING', 'NULLABLE', None, ()),
SchemaField('last_name', 'STRING', 'NULLABLE', None, ()),
SchemaField('dob', 'DATE', 'NULLABLE', None, ()),
SchemaField('addresses', 'RECORD', 'REPEATED', None, [SchemaField('status', 'STRING', 'NULLABLE', None, ()), SchemaField('address', 'STRING', 'NULLABLE', None, ()), SchemaField('city', 'STRING', 'NULLABLE', None, ()), SchemaField('state', 'STRING', 'NULLABLE', None, ()), SchemaField('zip', 'INT64', 'NULLABLE', None, ()), SchemaField('numberOfYears', 'INT64', 'NULLABLE', None, ())])
]
Part 2 is done
We created a Cloud Function to load data from Google Storage into BigQuery.
We created a schema.yaml file to hold all information about tables.
We come up with 6 different ways to process different types of data.
In Part 3 we'll deploy our Cloud Function and add bucket event trigger to invoke it.
We will use a shell script for this.
Then we will build full ETL pipeline with load monitoring using Firestore and error handling.

Thanks for reading!

Mike
Mike is a Machine Learning Engineer / Python / Java Script Full stack dev / Middle shelf tequila connoisseur and accomplished napper. Stay tuned, read me on Medium https://medium.com/@mshakhomirov/membership and receive my unique content.
Comments