Building ETL pipeline with load monitoring and error handling.
Welcome to part 3 of the tutorial series "Build a Data warehouse in the Cloud using BigQuery". This tutorial, demonstrates how to build a real-time (or close to real-time) analytics ETL pipeline using Cloud Functions. In Part 2 we wrote a Cloud function to load data from Google Storage into BigQuery.
Our Cloud function is built on top of the hybrid solution that we completed in Part 1
In Part 1 we created a streaming lambda to transfer our data files from AWS S3 to Google Storage. In Part2 we wrote a Cloud function to load different types of data in BigQuery. We will use it as a foundation for our ETL pipeline which will be responsible for loading, data monitoring ad error handling.
Before trying this article, follow the Python setup instructions in the BigQuery Quickstart Using Client Libraries .
Project layout:
Part 1: Sync only new/changed files from AWS S3 to GCP cloud storage.
Part 2: Loading data into BigQuery. Create tables using schemas. We'll use yaml to create config file.
You are here >>> Part 3: Create streaming ETL pipeline with load monitoring and error handling.
Prerequisites:
- Google developer account.
- Google Command Line Interface. Follow this article to install it: https://cloud.google.com/sdk/ .
-
Finally, we'll need Python to run our core application.
Just install Anaconda distribution .
Before starting, let's think about the architecture of our ETL pipeline.
-
Files of mixed types and formats are uploaded to the PROJECT_STAGING_FILES Cloud Storage bucket.
-
This event triggers streaming Cloud function we created in Part 2 .
-
Cloud function checks the file name and if there is a match for table name in schemas.yaml then data is parsed and inserted into relevant BigQuery table.
-
Cloud function will publish a success/error message in one of the following Cloud Pub/Sub topics:
- streaming_success_topic_staging
- streaming_error_topic_staging
-
Files will be moved from the FILES_SOURCE bucket to one of the following buckets:
- PROJECT_STAGING_FILES_ERROR
- PROJECT_STAGING_FILES_SUCCESS
We will log the result into Cloud Firestore and Stackdriver Logging .
The next diagram demonstrates ETL pipeline flow and it'scomponents. The solution is very similar to one suggested by Google in this article .
The difference is in details. Part 3 adds extra information about how to ingest different data types and formats.
We will be using schemas.yaml to create table definitions. So once our Cloud function is deployed we can successfuly forget about it. If we need to add a new table we'll just add a new record to schemas file.
And the third novelty is that we will add a few helper functions to read the ingestion results logging from Firestore collections.
We will be using BigQuery Python API in order to process and load files. You can find usage guides here - https://cloud.google.com/bigquery/docs/quickstarts/quickstart-client-libraries.
We will also need to have a Google service account in order to use Google account credentials. We have already done that in Part 1 but just in case you are only interested in this particular tutorial this page contains the official instructions for Google managed accounts: How to create service account. After this you will be able to download your credentials and use Google API programmatically with Node.js. Your credentials file will look like this (example):
./your-google-project-12345.json
{
"type": "service_account",
"project_id": "your-project",
"private_key_id": "1202355D6DFGHJK54A223423DAD34320F5435D",
"private_key": "-----BEGIN PRIVATE KEY-----\ASDFGHJKLWQERTYUILKJHGFOIUYTREQWEQWE4BJDM61T4S0WW3XKXHIGRV\NRTPRDALWER3/H94KHCKCD3TEJBRWER4CX9RYCIT1BY7RDBBVBCTWERTYFGHCVBNMLKXCVBNM,MRaSIo=\n-----END PRIVATE KEY-----\n",
"client_email": "your-project-adminsdk@your-project.iam.gserviceaccount.com",
"client_id": "1234567890",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/your-project-adminsdk%40your-project.iam.gserviceaccount.com"
}
OK, let's do it !
Clone Starter Repository
Run the following commands to clone the starter project and install the dependencies
git clone https://github.com/mshakhomirov/bigquery-etl-tutorial.git
cd bigquery-etl-tutorial
git checkout part3
The master branch includes base directory template for Part 1, with dependencies declared in package.json.
After you did git checkout part3etl you will be in branch for this part with all the Python code we need. It is slightly different from Part 2 as we added topics, firestore and 'move' files function.
Create source and destination buckets using Google command line interface
Use your Google account credentials (replace the file name to match yours) and in command line run this:
export GOOGLE_APPLICATION_CREDENTIALS="./client-50b5355d654a.json"
Then in your command line run these two commands which will create the dataset and a table:
$ gsutil mb -c regional -l europe-west2 gs://project_staging_files_success
$ gsutil mb -c regional -l europe-west2 gs://project_staging_files_error
If you don't have gsutils installed on your machine you could try using Cloud Shell .
Great! Now if you go to Google web console you should be able to see your new buckets.
Create Cloud Pub/Sub topics using CLI
Now let's create the topics we need to publish ingestion results into. They will be used to trigger two other Cloud functions which will be moving processed files into success/error bucket. Run this in your command line:
$ STREAMING_ERROR_TOPIC=streaming_error_topic_staging
$ gcloud pubsub topics create ${STREAMING_ERROR_TOPIC}
$ STREAMING_SUCCESS_TOPIC=streaming_success_topic_staging
$ gcloud pubsub topics create ${STREAMING_SUCCESS_TOPIC}
Run this to list your topics:
Great! The topics are there now.
Set up your Cloud Firestore database.
In the ideal scenario we would like to have a track record of each data file ingestion:
-
We want our Cloud Function to log each .file name it processed into Firestore daily collection.
-
We also would like to log ingestion status (success/error) and error message. This will be big help in case we need to fix corrupted data.
-
Duplication attempts might generate inacurate reports. We want to track those as well.
Let's create your Cloud Firestore instance, follow these steps:
- In the GCP console, go to Cloud Firestore.
- In the Choose a Cloud Firestore mode window, click Select Native Mode.
- In the Select a location list, select region>, and then click Create Database. Wait for the Cloud Firestore initialization to finish. It usually takes a few minutes.
Now let's deploy our cloud functions: streaming_staging which we wrote in Part 2 and two extra functions which will be responsible for handling successfull (streaming_success_staging) and error (streaming_error_staging) data ingestion and will move the file into a relevant bucket so we could investigate it later.
Deploy Cloud Functions
We will create a shell script for this. This is how our Cloud Function streaming_staging looks:
./main.py
'''
This simple a Cloud Function responsible for:
- Triggered by Google Storage create object event
- Loading data using schemas
- Loading data from different data file formats
- Publishing ingestion results to success/error topics
- Looging ingestion results to Firestore
'''
import json
import logging
import os
import traceback
from datetime import datetime
import io
import re
from six import StringIO
from six import BytesIO
from google.api_core import retry
from google.cloud import bigquery
from google.cloud import firestore
from google.cloud import pubsub_v1
from google.cloud import storage
import pytz
import pandas
import yaml
with open("./schemas.yaml") as schema_file:
config = yaml.load(schema_file)
import config as conf
ENV = os.getenv('ENV')
PROJECT_ID = os.getenv('GCP_PROJECT')
BQ_DATASET = conf.datasetname
ERROR_TOPIC = 'projects/%s/topics/%s' % (PROJECT_ID, conf.error_topic_name)
SUCCESS_TOPIC = 'projects/%s/topics/%s' % (PROJECT_ID, conf.success_topic_name)
CS = storage.Client()
BQ = bigquery.Client()
DB = firestore.Client()
PS = pubsub_v1.PublisherClient()
job_config = bigquery.LoadJobConfig()
"""
This is our Cloud Function:
"""
def streaming_staging(data, context):
bucketname = data['bucket']
filename = data['name']
timeCreated = data['timeCreated']
# try:
for table in config:
tableName = table.get('name')
# Check which table the file belongs to and load:
if re.search(tableName.replace('_', '-'), filename) or re.search(tableName, filename):
print('Loading into ', conf.datasetname, 'at ', _today())
tableSchema = table.get('schema')
_check_if_table_exists(table)
# Check source file data format. Depending on that we'll use different methods.
tableFormat = table.get('format')
# db_ref = DB.document(u'streaming_files_%s/%s' % (_today(),filename.replace('/', '\\')))
db_ref = DB.document(u'streaming_files_%s/%s' % (ENV,filename.replace('/', '\\')))
if _was_already_ingested(db_ref):
_handle_duplication(db_ref)
else:
try:
if tableFormat == 'NEWLINE_DELIMITED_JSON':
_load_table_from_uri(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'OUTER_ARRAY_JSON':
_load_table_from_json(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'SRC':
_load_table_as_src(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'OBJECT_STRING':
_load_table_from_object_string(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'DF':
_load_table_from_dataframe(data['bucket'], data['name'], tableSchema, tableName)
elif tableFormat == 'DF_NORMALIZED':
_load_table_as_df_normalized(data['bucket'], data['name'], tableSchema, tableName)
_handle_success(db_ref)
except Exception:
_handle_error(db_ref)
def _insert_rows_into_bigquery(bucket_name, file_name,tableSchema,tableName):
blob = CS.get_bucket(bucket_name).blob(file_name)
row = json.loads(blob.download_as_string())
print('row: ', row)
table = BQ.dataset(BQ_DATASET).table(tableName)
errors = BQ.insert_rows_json(table,
json_rows=[row],
row_ids=[file_name],
retry=retry.Retry(deadline=30))
print(errors)
if errors != []:
raise BigQueryError(errors)
def _load_table_from_json(bucket_name, file_name, tableSchema, tableName):
blob = CS.get_bucket(bucket_name).blob(file_name)
#! source data file format must be outer array JSON:
"""
[
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]},
{"id":"2","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
]
"""
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND'
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
load_job = BQ.load_table_from_json(
body,
table_id,
job_config=job_config,
)
load_job.result() # Waits for table load to complete.
print("Job finished.")
def _load_table_as_src(bucket_name, file_name, tableSchema, tableName):
# ! source file must be outer array JSON
# ! this will work for CSV where a row is A JSON string --> SRC column (Snowflake like)
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.CSV,
# something that doesn't exist in your data file:
job_config.field_delimiter =";"
# Notice that ';' worked because the snippet data does not contain ';'
job_config.write_disposition = 'WRITE_APPEND',
data_str = u"\n".join(json.dumps(item) for item in body)
print('data_str :', data_str)
data_file = io.BytesIO(data_str.encode())
print('data_file :', data_file)
load_job = BQ.load_table_from_file(
data_file,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _load_table_from_object_string(bucket_name, file_name, tableSchema, tableName):
# ! source file must be object string, e.g.:
"""
{"id": "1", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}{"id": "2", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
"""
# ! we will convert body to a new line delimited JSON
blob = CS.get_bucket(bucket_name).blob(file_name)
blob = blob.download_as_string().decode()
# Transform object string data into JSON outer array string:
blob = json.dumps('[' + blob.replace('}{', '},{') + ']')
# Load as JSON:
body = json.loads(blob)
# Create an array of string elements from JSON:
jsonReady = [json.dumps(record) for record in json.loads(body)]
# Now join them to create new line delimited JSON:
data_str = u"\n".join(jsonReady)
print('data_file :', data_str)
# Create file to load into BigQuery:
data_file = StringIO(data_str)
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND',
load_job = BQ.load_table_from_file(
data_file,
table_id,
job_config=job_config,
)
load_job.result() # Waits for table load to complete.
print("Job finished.")
"""
This function will check if table exists, otherwise create it.
Will also check if tableSchema contains partition_field and
if exists will use it to create a table.
"""
def _check_if_table_exists(tableData):
# get table_id reference
tableName = tableData.get('name')
tableSchema = tableData.get('schema')
table_id = BQ.dataset(BQ_DATASET).table(tableName)
# check if table exists, otherwise create
try:
BQ.get_table(table_id)
except Exception:
logging.warn('Creating table: %s' % (tableName))
schema = create_schema_from_yaml(tableSchema)
table = bigquery.Table(table_id, schema=schema)
# Check if partition_field exists in schema definition and if so use it to create the table:
if (tableData.get('partition_field')):
table.time_partitioning = bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field=tableData.get('partition_field'), #"date", # name of column to use for partitioning
# expiration_ms=7776000000,
) # 90 days
table = BQ.create_table(table)
print("Created table {}.{}.{}".format(table.project, table.dataset_id, table.table_id))
# BQ.create_dataset(dataset_ref)
def _load_table_from_uri(bucket_name, file_name, tableSchema, tableName):
# ! source file must be like this:
"""
{"id": "1", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
{"id": "2", "first_name": "John", "last_name": "Doe", "dob": "1968-01-22", "addresses": [{"status": "current", "address": "123 First Avenue", "city": "Seattle", "state": "WA", "zip": "11111", "numberOfYears": "1"}, {"status": "previous", "address": "456 Main Street", "city": "Portland", "state": "OR", "zip": "22222", "numberOfYears": "5"}]}
"""
# ! source file must be the same.
#! if source file is not a NEWLINE_DELIMITED_JSON then you need to load it with blob, convert to JSON and then load as file.
uri = 'gs://%s/%s' % (bucket_name, file_name)
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
print(schema)
job_config.schema = schema
job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON,
job_config.write_disposition = 'WRITE_APPEND',
load_job = BQ.load_table_from_uri(
uri,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _load_table_from_dataframe(bucket_name, file_name, tableSchema, tableName):
"""
Source data file must be outer JSON
"""
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
df = pandas.DataFrame(
body,
# In the loaded table, the column order reflects the order of the
# columns in the DataFrame.
columns=["id", "first_name","last_name","dob","addresses"],
)
df['addresses'] = df.addresses.astype(str)
df = df[['id','first_name','last_name','dob','addresses']]
load_job = BQ.load_table_from_dataframe(
df,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _load_table_as_df_normalized(bucket_name, file_name, tableSchema, tableName):
"""
Source data file must be outer JSON
"""
blob = CS.get_bucket(bucket_name).blob(file_name)
body = json.loads(blob.download_as_string())
table_id = BQ.dataset(BQ_DATASET).table(tableName)
schema = create_schema_from_yaml(tableSchema)
job_config.schema = schema
df = pandas.io.json.json_normalize(data=body, record_path='addresses',
meta=[ 'id' ,'first_name', 'last_name', 'dob']
, record_prefix='addresses_'
,errors='ignore')
df = df[['id','first_name','last_name','dob','addresses_status','addresses_address','addresses_city','addresses_state','addresses_zip','addresses_numberOfYears']]
load_job = BQ.load_table_from_dataframe(
df,
table_id,
job_config=job_config,
)
load_job.result()
print("Job finished.")
def _handle_error(db_ref):
message = 'Error streaming file \'%s\'. Cause: %s' % (db_ref.id, traceback.format_exc())
doc = {
u'success': False,
u'error_message': message,
u'when': _now()
}
db_ref.set(doc)
PS.publish(ERROR_TOPIC, message.encode('utf-8'), file_name=db_ref.id.replace('\\', '/'))
logging.error(message)
def create_schema_from_yaml(table_schema):
schema = []
for column in table_schema:
schemaField = bigquery.SchemaField(column['name'], column['type'], column['mode'])
schema.append(schemaField)
if column['type'] == 'RECORD':
schemaField._fields = create_schema_from_yaml(column['fields'])
return schema
class BigQueryError(Exception):
'''Exception raised whenever a BigQuery error happened'''
def __init__(self, errors):
super().__init__(self._format(errors))
self.errors = errors
def _format(self, errors):
err = []
for error in errors:
err.extend(error['errors'])
return json.dumps(err)
def _now():
return datetime.utcnow().replace(tzinfo=pytz.utc).strftime('%Y-%m-%d %H:%M:%S %Z')
def _today():
return datetime.utcnow().replace(tzinfo=pytz.utc).strftime('%Y-%m-%d')
def _was_already_ingested(db_ref):
status = db_ref.get()
return status.exists and status.to_dict()['success']
def _handle_duplication(db_ref):
dups = [_now()]
data = db_ref.get().to_dict()
if 'duplication_attempts' in data:
dups.extend(data['duplication_attempts'])
db_ref.update({
'duplication_attempts': dups
})
logging.warn('Duplication attempt streaming file \'%s\'' % db_ref.id)
def _handle_success(db_ref):
message = 'File \'%s\' streamed into BigQuery' % db_ref.id
doc = {
u'success': True,
u'when': _now()
}
db_ref.set(doc)
PS.publish(SUCCESS_TOPIC, message.encode('utf-8'), file_name= db_ref.id.replace('\\', '/'))
logging.info(message)
Looks huge but we only added a few functions. Check Part 2 to see the difference.
main.py contains 6 different functions to process data we have in our source files. Each of them handles one of the most popular scenarios to process the data in modern datalakes. We described source data files types in the beginning of Part2 article but essentially they are different types of JSON and CSV. Have a look at ./test_files folder. Each file with table_ prefix represents a use case and has it's own data structure. Also take your time to familiarise yourself with the code or just keep reading and I will talk you through each step.
Now let's create a shell script to deploy it ./deploy.sh.
It is slightly different from Part1 deploy.sh We'll add ENVIRONMENT variable and labels to simplify future deployment and monitoring.
#!/bin/sh
# chmod +x the_file_name
ENVIRONMENT=$1
FUNCTION="streaming_"${ENVIRONMENT}
PROJECT="your-project"
BUCKET="project_"${ENVIRONMENT}"_files"
# set the gcloud project
gcloud config set project ${PROJECT}
gcloud functions deploy ${FUNCTION} \
--region=europe-west2 \
--stage-bucket=gs://your-project-functions-${ENVIRONMENT}/ \
--runtime python37 \
--trigger-resource ${BUCKET} \
--trigger-event google.storage.object.finalize \
--update-labels=service=functions-bigquery-${ENVIRONMENT} \
--set-env-vars ENV=${ENVIRONMENT}
Have a look at this file. Last two commands set labels and environment variable 'staging'. For example, 'staging' environment variable will be used to create Firestore collection called 'streaming_collection_staging. Replace "your-project" with your project name and we are ready to go.
Now in your command line run ./deploy.sh staging. And after that you should be able to see JSON response with deployment progress saying that your cloud function has been successfully deployed.
Now let's deploy two functions which will move ingested file to success/error bucket depending on the result.
Essentially it is the same function ./functions/move_file/main.py but we will name them differently and each will have it's own trigger topic.
./functions/move_file/main.py:
'''
This Cloud function moves a file from one bucket to another
'''
import base64
import os
import logging
from google.cloud import storage
CS = storage.Client()
def move_file(data, context):
'''This function is executed from a Cloud Pub/Sub'''
message = base64.b64decode(data['data']).decode('utf-8')
file_name = data['attributes']['file_name']
logging.info(data)
# logging.info('data[\'attributes\'] \'%s\' --- file_name: \'%s\' ',
# data['attributes'],
# data['attributes']['file_name'])
source_bucket_name = os.getenv('SOURCE_BUCKET')
source_bucket = CS.get_bucket(source_bucket_name)
source_blob = source_bucket.blob(file_name)
destination_bucket_name = os.getenv('DESTINATION_BUCKET')
destination_bucket = CS.get_bucket(destination_bucket_name)
source_bucket.copy_blob(source_blob, destination_bucket, file_name)
source_blob.delete()
logging.info('File \'%s\' moved from \'%s\' to \'%s\': \'%s\'',
file_name,
source_bucket_name,
destination_bucket_name,
message)
To deploy the first function run this in your command line (or Cloud Shell:
# streaming_error_staging function to copy files in case there was an error during BigQuery import:
gcloud functions deploy streaming_error_staging --region=europe-west2 \
--source=./functions/move_file \
--entry-point=move_file --runtime=python37 \
--stage-bucket=gs://your-project-functions-staging/ \
--trigger-topic=streaming_error_topic_staging \
--set-env-vars SOURCE_BUCKET=project_staging_files,DESTINATION_BUCKET=project_staging_files_error
Change staging suffix to whatever environment you use. This is just a shell command and we can always wrap it all up into one script with variables in the end.
Notice that we have just set up a trigger and two environment variables for that Cloud function:
--trigger-topic=streaming_error_topic_staging \
--set-env-vars SOURCE_BUCKET=project_staging_files,DESTINATION_BUCKET=project_staging_files_error
Now run this in your command line to check function status:
$ gcloud functions describe streaming_error_staging --region=europe-west2 \
--format="table[box](entryPoint, status, eventTrigger.eventType)"
Great. If you see this then your function has been successfully deployed:
┌─────────────┬────────┬─────────────────────────────┐
│ ENTRY_POINT │ STATUS │ EVENT_TYPE │
├─────────────┼────────┼─────────────────────────────┤
│ move_file │ ACTIVE │ google.pubsub.topic.publish │
└─────────────┴────────┴─────────────────────────────┘
Now let's deploy the second function to move file to success bucket:
# streaming_success_staging function to copy files
gcloud functions deploy streaming_success_staging --region=europe-west2 \
--source=./functions/move_file \
--entry-point=move_file --runtime=python37 \
--stage-bucket=gs://your-project-functions-staging/ \
--trigger-topic=streaming_success_topic_staging \
--set-env-vars SOURCE_BUCKET=project_staging_files,DESTINATION_BUCKET=project_staging_files_success
It is almost the same. We just changed the trigger and destination bucket:
$ gcloud functions describe streaming_success_staging --region=europe-west2 \
> --format="table[box](entryPoint, status, eventTrigger.eventType)"
┌─────────────┬────────┬─────────────────────────────┐
│ ENTRY_POINT │ STATUS │ EVENT_TYPE │
├─────────────┼────────┼─────────────────────────────┤
│ move_file │ ACTIVE │ google.pubsub.topic.publish │
└─────────────┴────────┴─────────────────────────────┘
Let's test our Cloud function.
All we need to do in order to run a test is to copy a file to our source bucket called project_staging_files. In your command line run this:
gsutil cp ./test_files/data_new_line_delimited_json.json gs://project_staging_files/table-7_data_new_line_delimited_json.json
Now go to Google web console and run a query: select * from `your-project.staging.table_7`:
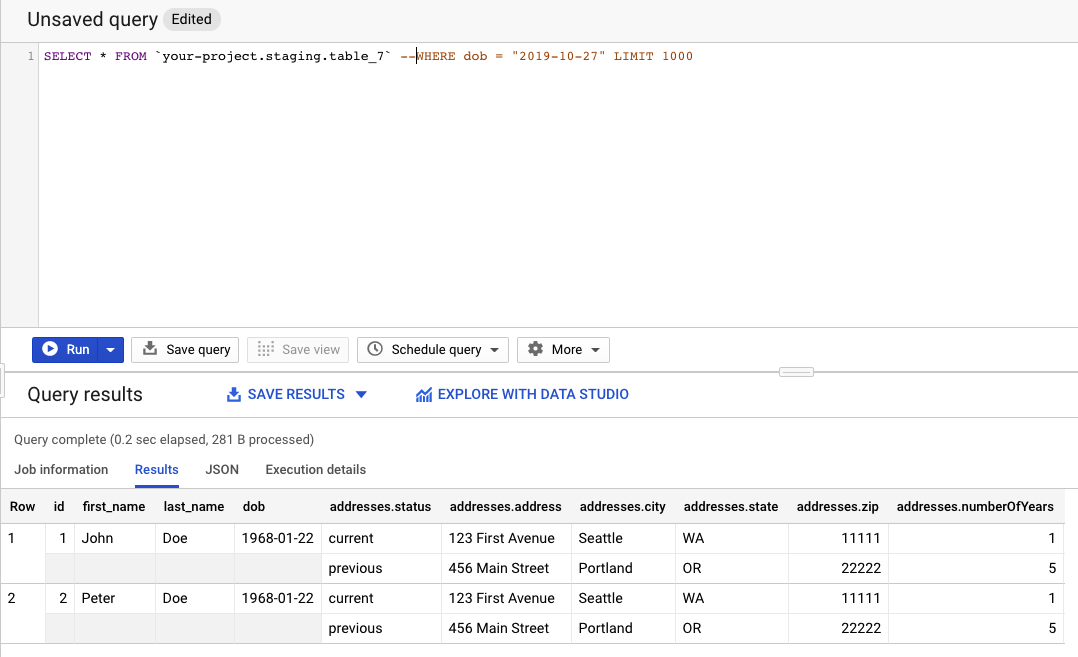
Great! Records from your file have been successfully loaded into BigQuery. Let's see what we have in Firestore. Go to Google web console and select Firestore:
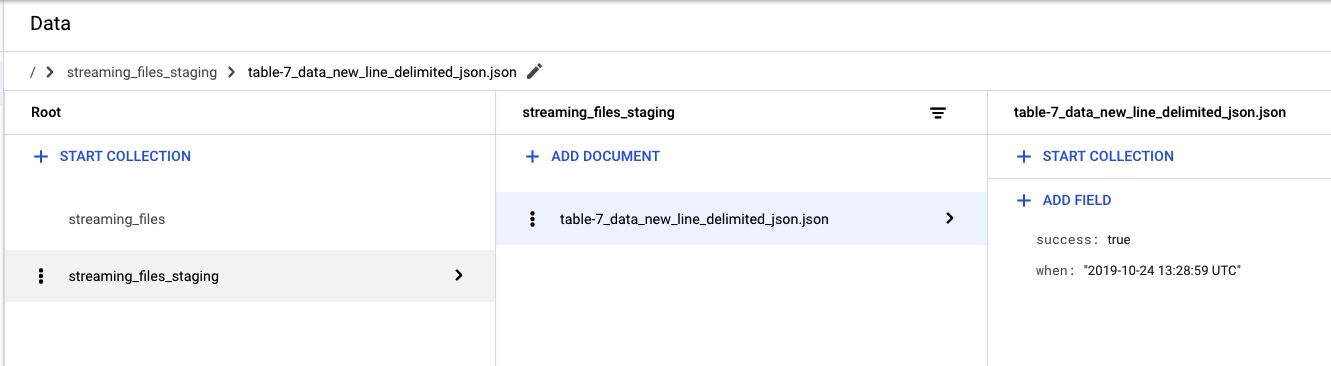
Now let's go to our files success bucket. We should find our file successfully moved from project_staging_files to project_staging_files_success:
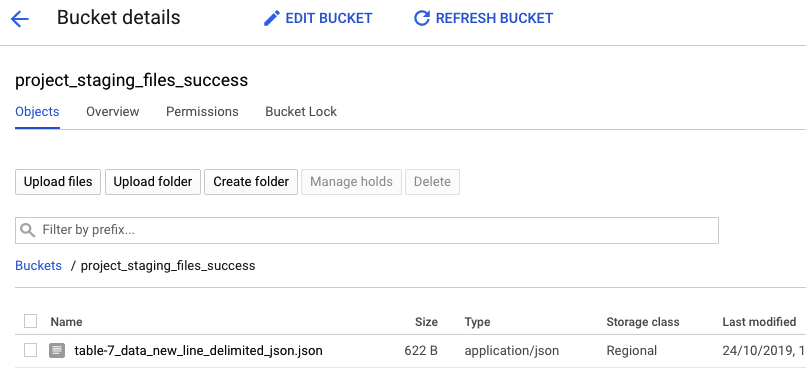
Try running cp command again on that file and you will see duplicattion attempt record in Firestore which means everything works as expected:
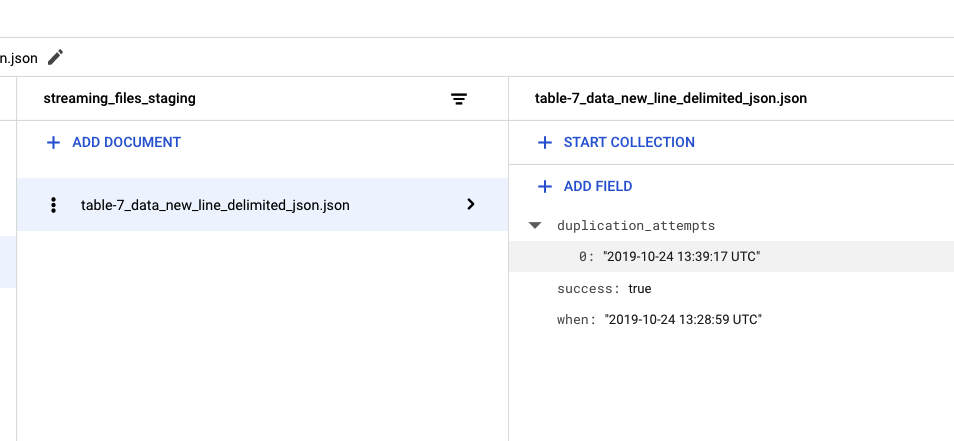
Now let's test error scenario. Run this in your command line:
gsutil cp ./test_files/data_new_line_delimited_json.json gs://project_staging_files/table-5_data_new_line_delimited_json.json
We have just tried to copy the same file to a wrong table. We named our file meant to be for table 7 as /table-5_data_new_line_delimited_json.json.
Our cloud function read the file name and decided to insert it's contents into table 5 obviously using a method which is not suitable for that data.
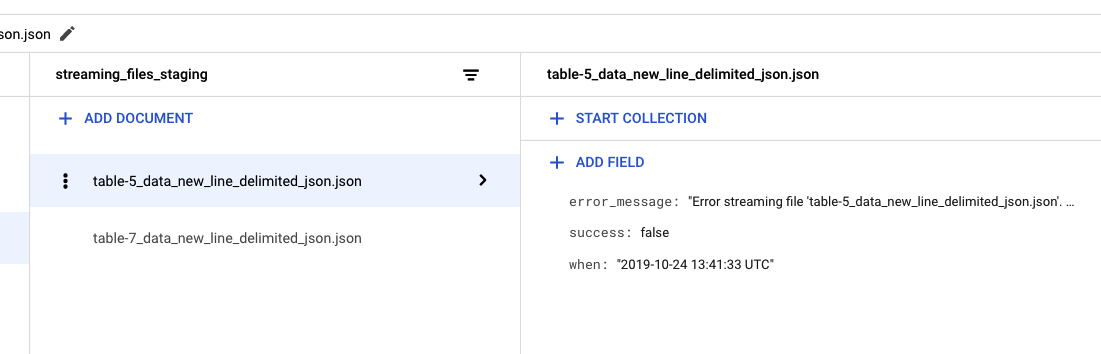
Here we received an error and file has been left in project_staging_files folder for further investigation.
Nice! Data load pipeline seems to be working fine. Time to do some load monitoring ad set up alerts.
Alerts and Load monitoring in BigQuery
Firestore database we set up earlier makes it easier to find and fix data ingestion errors. We can filter them by using standard Python API for Cloud Firestore .
Query request looks like that:
firestore/show_streaming_errors.py
db = firestore.Client()
docs = db.collection(u'streaming_files')\
.where(u'success', u'==', False)\
.get()
To run this query on your machine do the following:
- Create a virtual environment in your firestore folder.
-
Install the Python Cloud Firestore module in your virtual environment.
-
Query the database to get error records:
$ python ./functions/firestore/show_streaming_errors.py
$ pip install virtualenv
$ virtualenv functions/firestore
$ source functions/firestore/bin/activate
$ pip install google-cloud-firestore
./functions/firestore/show_streaming_errors.py.py will run the query and pull the results out:
$ $ python ./functions/firestore/show_streaming_errors.py
./functions/firestore/show_streaming_errors.py:35: DeprecationWarning: 'Query.get' is deprecated: please use 'Query.stream' instead.
.where(u'success', u'==', False)\
+------------------------------------------+--------------------------+----------------------------------------------------------------------------------+
| File Name | When | Error Message |
+------------------------------------------+--------------------------+----------------------------------------------------------------------------------+
| table-5_data_new_line_delimited_json.jso | 2019-10-24 13:41:33 UTC | Error streaming file 'table-5_data_new_line_delimited_json.json'. Cause: Trace.. |
+------------------------------------------+--------------------------+----------------------------------------------------------------------------------+
Before it shows the results it may return error asking to provide Google credentials. You know what to do, right?
$ export GOOGLE_APPLICATION_CREDENTIALS="/Users/mikeshakhomirov/Documents/creds/your-project-5dsfsd333.json"
How to get the list of all files from Firebase for today.
In order to get a filtered list of all records since midnight we will use compound filtering like so:
db = firestore.Client()
docs = db.collection(u'streaming_files')\
.where(u'when', u'>=', _today())\
.where(u'when', u'<=', '2019-10-24 00:40:00')\
.stream()
We have also adjusted final output function to display all ingestion results:
_print_header()
for doc in docs:
data = doc.to_dict()
name = doc.id.ljust(NAME_SIZE)[:NAME_SIZE]
# name = doc.id
when = data['when'].ljust(WHEN_SIZE)[:WHEN_SIZE]
if ('error_message' in data):
error_message = data['error_message']
message = (error_message[:MESSAGE_SIZE-2] + '..') \
if len(error_message) > MESSAGE_SIZE \
else error_message.ljust(MESSAGE_SIZE)[:MESSAGE_SIZE]
elif('duplication_attempts' in data):
message = 'duplication_attempt'
else:
message = 'success'
# print(data)
print(u'| %s | %s | %s |' % (name, when, message))
_print_footer()
Check the full file ./functions/firestore/show_only_today.py
In order to execute it, in your command line run this:
$ python ./functions/firestore/show_only_today.py
Delete old documents from Firestore
In order to delete old documents we will create delete_where.py. We jus need to slightly change show_only_today.py by adding delete method to final function:
./functions/firestore/delete_where.py
...
print(u'| %s | %s | %s |' % (name, when, message))
# Now delete doc
doc.reference.delete()
deleted = deleted + 1
_print_footer()
print(u'files deleted : ', deleted)
Now just enter the date like below and run $ python ./functions/firestore/delete.py
...
db = firestore.Client()
docs = db.collection(u'streaming_files_staging')\
.where(u'when', u'<=', '2019-10-12 00:00:00')\
.stream()
...
Delete old documents from Firestore by name
Check file delete_by_name.py:
...
files_to_delete = [u'table-5_data_new_line_delimited_json.json',u'some_folder\\table-5_data_new_line_delimited_json.json']
db = firestore.Client()
for name in files_to_delete:
# Get file contents by name:
doc_ref = db.collection(u'streaming_files_staging').document(name).get()
data = doc_ref.to_dict()
doc_ref = db.collection(u'streaming_files_staging').document(name)
print('+ Deleting ', name)
print('+++ records ', data)
doc_ref.delete()
print('===============')
print('===============')
for name in files_to_delete:
doc_ref = db.collection(u'streaming_files').document(name).get()
data = doc_ref.to_dict()
print(data, 'records left in ', name)
...
Success!
Run deactivate to deactivate your environment.
Set up notification alerts
In our production environment we would like to keep everything under control and be notified when data ingestion goes wrong.
Our Cloud function generates logs in Stackdriver logging . So we will create a custom metric for ingestion error.
Then we will create alerting policy to notify us by email whenever data load fails.
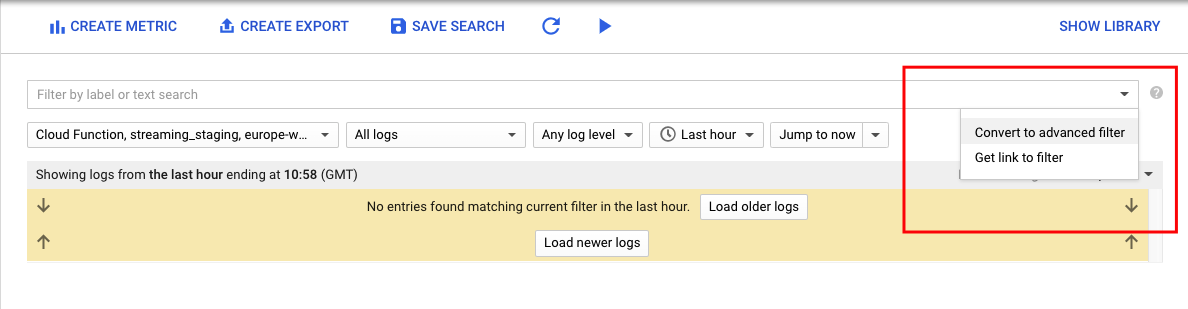
- Go to Google web console Logs-based metrics page.
- Click Create Metric.
- In the Filter list, select Convert to advanced filter.
- In the advanced filter, paste the following configuration.
-
-
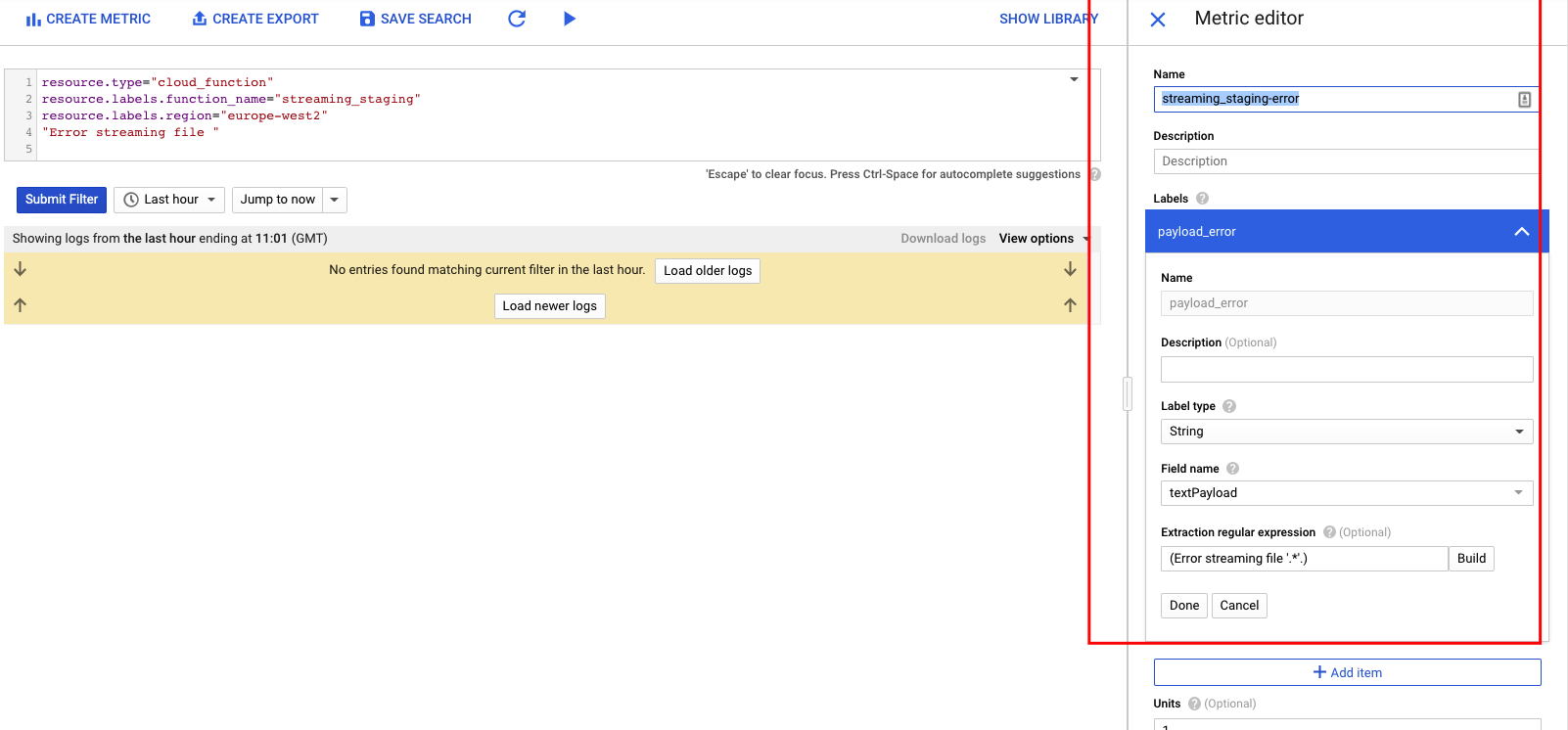
In the Metric Editor, fill in the following fields and then click Create Metric.
- In the Name field, enter streaming_staging-error .
- In the Label section, enter payload_error in the Name field.
- In the Label type list, select String.
- In the Field name list, select textPayload.
- In the Extraction regular expression field, enter (Error streaming file '.*'.).
- In the Type list, select Counter.
- Now go to Create a Policy. page.
-
In the Create a Policy window, complete the following steps.
- Click Add Condition.
- Complete the following fields, and then click Save.
- In the Title field, enter streaming-staging-error-condition.
- In the Metric field, enter logging/user/streaming_staging-error.
- In the Condition trigger If list, select Any time series violates.
- In the Condition list, select is above.
- In the Threshold field, enter 0.
- In the For list, select 1 minute.
- In the Notification Channel Type list, select Email, enter your email address, and then click Add Notification Channel.
- In the Name this policy field, enter streaming-error-alert, and then click Save.
resource.type="cloud_function"
resource.labels.function_name="streaming_staging"
resource.labels.region="europe-west2"
"Error streaming file "

Great! After saving Stackdriver will start sending notifications every time data load fails.
Part 3 is done
Don't forget to clean up and delete everything to avoid incurring charges to your Google Cloud Platform account for the resources used in this tutorial
We have deployed a Cloud Function to load data from Google Storage into BigQuery.
We've created an ETL pipeline to load data stored in Google Storage in different formats
We've set up data ingestion status logging with Firestore.
We've also set up Stackdriver Alerts to send notifications by email in case aomething goes wrong.
In Part 4 we'll schedule a few SQL scripts and set up a bunch of nice looking reports made with Google Data Studio
Thanks for reading!


Stay tuned! We post weekly.

Mike
Mike is a Machine Learning Engineer / Python / Java Script Full stack dev / Middle shelf tequila connoisseur and accomplished napper. Stay tuned, read me on Medium https://medium.com/@mshakhomirov/membership and receive my unique content.
Comments